


Large language models (LLMs) have showcased remarkable capabilities in generating content and solving complex problems across various domains. However, a notable challenge persists in their ability to perform multi-step deductive reasoning. This type of reasoning requires a coherent and logical thought process over extended interactions, which current LLMs need help with due to their training methodologies.
A primary issue with current LLMs is their limited capability in multi-step deductive reasoning. This limitation stems from their training on next-token prediction, which does not equip them to apply logical rules or maintain deep contextual understanding. As a result, these models often need help to produce coherent and logically consistent responses in tasks that demand such reasoning. This shortfall is particularly evident in tasks that involve complex logical sequences and deep contextual analysis.
Existing methods to enhance LLMs’ reasoning capabilities include integrating external memory databases and employing techniques like Recursive Model Training (RMT). For example, GPT-3.5 and GPT-4 can extend token caps through engineering prompts or technologies such as RMT. However, these approaches introduce their challenges. One significant issue is the potential embedding of biases from the retrieval models into the LLMs, which can affect the models’ accuracy and stability. Also, handling long sequence limitations in multi-turn dialogues remains a considerable obstacle.
Researchers from the University of Auckland have introduced ChatLogic, a novel framework designed to augment LLMs with a logical reasoning engine. This framework aims to enhance multi-step deductive reasoning by converting logic problems into symbolic representations that LLMs can process. ChatLogic leverages LLMs’ situational understanding and integrates symbolic memory to improve their reasoning capabilities. This innovative approach is specifically targeted at overcoming the limitations of current LLMs in multi-step reasoning tasks.
ChatLogic employs a unique approach called ‘Mix-shot Chain of Thought’ (CoT), which combines various prompt engineering techniques to guide LLMs efficiently through logical reasoning steps. This method transforms natural language queries into logical symbols using pyDatalog, enhancing the stability and precision of the reasoning process. The framework includes semantic and syntax correction modules that refine logic programs, significantly improving their practical application. This dual-phase correction ensures that the generated code aligns closely with the intended logic, thereby enhancing the overall performance of the LLMs in reasoning tasks.
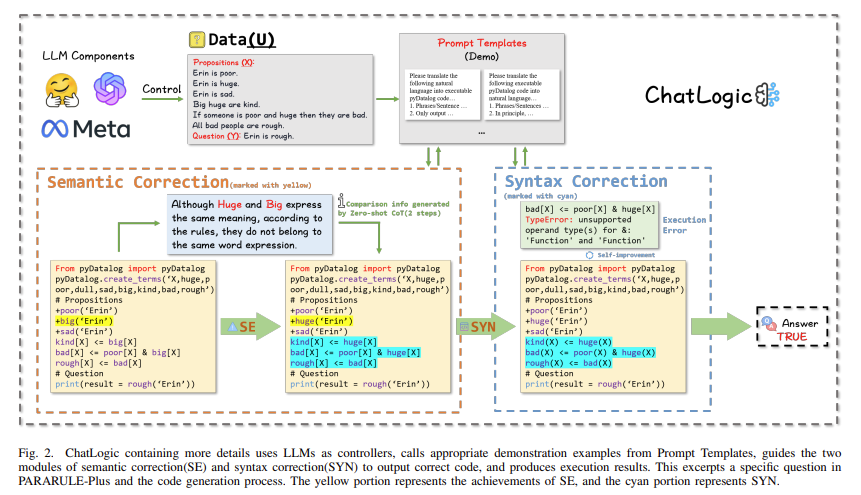
Experimental results demonstrate that LLMs integrated with ChatLogic significantly outperform baseline models in multi-step reasoning tasks. For instance, on the PARARULE-Plus dataset, GPT-3.5 with ChatLogic achieved an accuracy of 0.5275, compared to 0.344 for the base model. Similarly, GPT-4 with ChatLogic showed an accuracy of 0.73, while the base model only reached 0.555. These improvements are particularly notable in high-precision scenarios, where the accuracy and reliability of reasoning are critical. ChatLogic effectively mitigates information loss, addressing the long sequence limitation in adopting LLMs for multi-step reasoning tasks.

Further analysis of the CONCEPTRULES datasets also highlights the efficacy of ChatLogic. For the simplified version of CONCEPTRULES V1, GPT-3.5 with ChatLogic achieved an accuracy of 0.69, compared to 0.57 for the base model. For GPT-4, the accuracy with ChatLogic was 0.96, showing a slight improvement over the base model’s 0.95. These results underscore the critical role of logical reasoning engines in enhancing the capabilities of LLMs across different tasks and datasets.

In conclusion, ChatLogic presents a robust solution to the multi-step reasoning limitations of current LLMs. By integrating logical reasoning engines and employing innovative prompt engineering techniques, the researchers have significantly enhanced the accuracy and reliability of LLMs in complex reasoning tasks. This advancement holds substantial potential for various applications, including customer service, healthcare, and education, where precise and logical responses are crucial. The framework’s ability to improve reasoning performance while maintaining high accuracy makes it a valuable addition to artificial intelligence and natural language processing.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post Researchers from the University of Auckland Introduced ChatLogic: Enhancing Multi-Step Reasoning in Large Language Models with Over 50% Accuracy Improvement in Complex Tasks appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]