


Document understanding (DU) focuses on the automatic interpretation and processing of documents, encompassing complex layout structures and multi-modal elements such as text, tables, charts, and images. This task is essential for extracting and utilizing the vast amounts of information contained in documents generated annually.
One of the critical challenges lies in understanding long-context documents that span many pages and require comprehension across various modalities and pages. Traditional single-page DU models struggle with this, making it crucial to develop benchmarks to evaluate models’ performance on lengthy documents. Researchers have identified that these long-context documents necessitate specific capabilities such as localization and cross-page comprehension, which are not adequately addressed by current single-page DU datasets.
Current methods for DU involve Large Vision-Language Models (LVLMs) such as GPT-4o, Gemini-1.5, and Claude-3, developed by companies like OpenAI and Anthropic. These models have shown promise on single-page tasks but need help with long-context document understanding due to the need for multi-page comprehension and integrating multimodal elements. This gap in capability underscores the importance of creating comprehensive benchmarks to push the development of more advanced models.
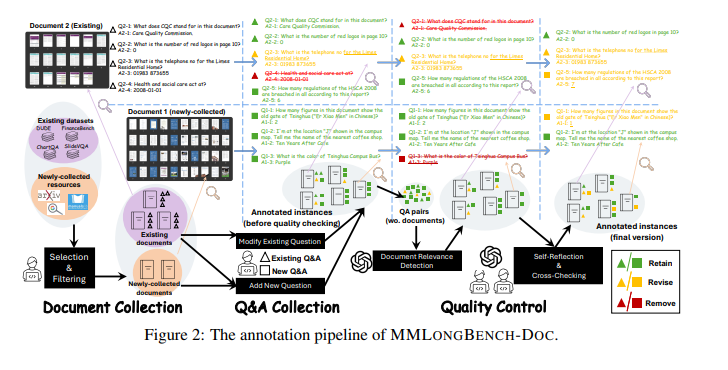
Researchers from institutions including Nanyang Technological University, Shanghai AI Laboratory, and Peking University have introduced MMLongBench-Doc, a comprehensive benchmark designed to evaluate the long-context DU capabilities of LVLMs. This benchmark includes 135 PDF-formatted documents from diverse domains, averaging 47.5 pages and 21,214.1 textual tokens. It features 1,091 questions requiring evidence from text, images, charts, tables, and layout structures, with a significant portion necessitating cross-page comprehension. This rigorous benchmark aims to push the boundaries of current DU models.
In-depth, the methodology involves using screenshots of document pages as inputs to LVLMs, comparing their performance with traditional OCR-parsed text models. The benchmark’s construction was meticulous, with ten expert annotators editing questions from existing datasets and creating new ones for comprehensiveness. The annotation process ensured high quality through a three-round, semi-automatic reviewing process. This approach highlighted the need for models to handle lengthy documents comprehensively, making MMLongBench-Doc a critical tool for evaluating and improving DU models.
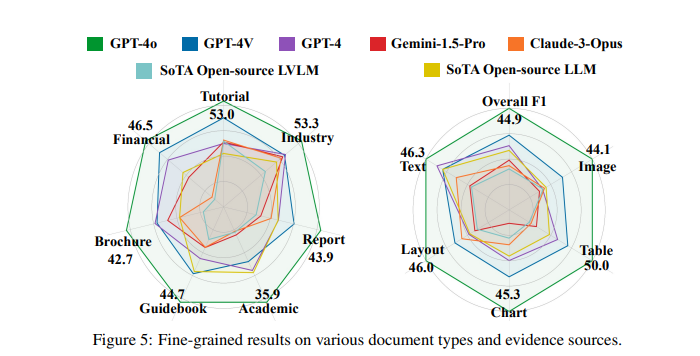
The performance evaluations revealed that LVLMs generally struggle with long-context DU. For instance, the best-performing model, GPT-4o, achieved an F1 score of 44.9%, while the second-best, GPT-4V, scored 30.5%. Other models, such as Gemini-1.5 and Claude-3, showed even lower performance. These results indicate the substantial challenges in long-context DU and the necessity for further advancements. The study compared these results with OCR-based models, noting that some LVLMs performed worse than single-modal LLMs when fed with lossy OCR-parsed text.
The detailed results highlighted that while LVLMs can handle multi-modal inputs to some extent, their capabilities still need to be improved. For example, 33.0% of the questions in the benchmark were cross-page questions requiring multi-page comprehension, and 22.5% were designed to be unanswerable to detect potential hallucinations. This rigorous testing underscored the need for more capable LVLMs. Proprietary models outperformed open-source ones, attributed to their higher acceptable image numbers and maximum image resolutions.

In conclusion, this study underscores the complexity of long-context document understanding and the necessity for advanced models capable of effectively processing and comprehending lengthy, multi-modal documents. The MMLongBench-Doc benchmark, developed by collaborating with leading research institutions, is a valuable tool for evaluating and improving these models’ performance. The study’s findings highlight current models’ significant challenges and the need for continued research and development in this area to achieve more effective and comprehensive DU solutions.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post MMLongBench-Doc: A Comprehensive Benchmark for Evaluating Long-Context Document Understanding in Large Vision-Language Models appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #ComputerVision #EditorsPick #Staff #TechNews #Technology [Source: AI Techpark]