


Deepset and Mixedbread have taken a bold step toward addressing the imbalance in the AI landscape that predominantly favors English-speaking markets. They have introduced a groundbreaking open-source German/English embedding model, deepset-mxbai-embed-de-large-v1, to enhance multilingual capabilities in natural language processing (NLP).
This model is based on intfloat/multilingual-e5-large and has undergone fine-tuning on over 30 million pairs of German data, specifically tailored for retrieval tasks. One of the key metrics used to evaluate retrieval tasks is NDCG@10, which measures the accuracy of ranking results compared to an ideally ordered list. Deepset-mxbai-embed-de-large-v1 has set a new standard for open-source German embedding models, competing favorably with commercial alternatives.
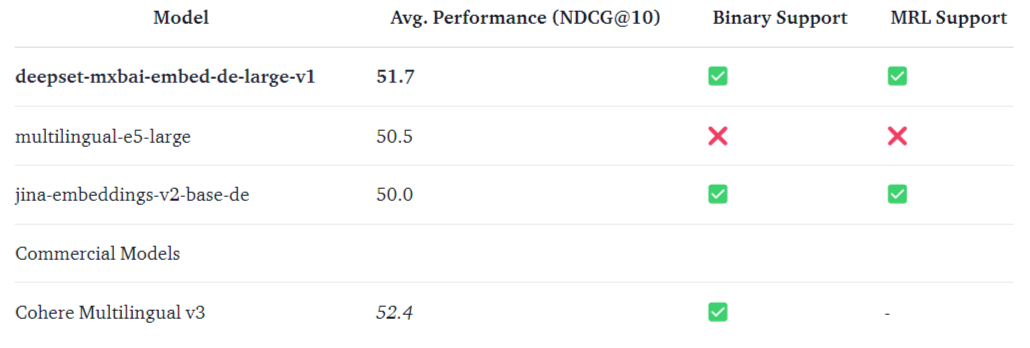
The deepset-mxbai-embed-de-large-v1 model has demonstrated an average performance of 51.7 on the NDCG@10 metric, outpacing other models such as multilingual-e5-large and jina-embeddings-v2-base-de. This performance underscores its reliability and effectiveness in handling German language tasks, making it a valuable tool for developers and researchers.
The developers have focused on optimizing storage and inference efficiency. Two innovative techniques have been employed: Matryoshka Representation Learning (MRL) and Binary Quantization.
- Matryoshka Representation Learning reduces the number of output dimensions in the embedding model without significant accuracy loss by modifying the loss function to prioritize important information in the initial dimensions. This allows for the truncation of later dimensions, enhancing efficiency.
- Binary Quantization converts float32 values to binary values, significantly reducing memory and disk space usage while maintaining high performance during inference. These optimizations make the model not only powerful but also resource-efficient.
Users can readily integrate deepset-mxbai-embed-de-large-v1 with the Haystack framework using components like SentenceTransformersDocumentEmbedder and SentenceTransformersTextEmbedder. Mixedbread provides seamless integration through MixedbreadDocumentEmbedder and MixedbreadTextEmbedder. To use the model with Haystack’s Sentence Transformers Embedders, users must install ‘mixedbread-ai-haystack’ and export their Mixedbread API key to ‘MXBAI_API_KEY.’
In conclusion, building on the success of the German BERT model, Deepset and Mixedbread anticipate that their new state-of-the-art embedding model will empower the German-speaking AI community to develop innovative products, particularly in retrieval-augmented generation (RAG) and beyond.
Check out the Details and Model. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post Deepset-Mxbai-Embed-de-Large-v1 Released: A New Open Source German/English Embedding Model appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]