


Traditional policy learning uses sampled trajectories from a replay buffer or behavior demonstrations to learn policies or trajectory models that map from state to action. This approach models a narrow behavior distribution. However, there is a challenge to guide high-dimensional output generation using low-dimensional demonstrations. Diffusion models have shown highly competitive performance on tasks like text-to-image synthesis. This success supports work toward policy network generation as a conditional denoising diffusion process. Refining noise into structured parameters consistently, the diffusion-based generator can discover various policies with superior performance and robust policy parameter space.
Existing methods in this area include Parameter Generation and Learning to Learn for Policy Learning. Parameter Generation has been a significant research focus since the introduction of Hypernetworks, which led to various studies on predicting neural network weights. For example, Hypertransformer uses Transformers to generate weights for each layer of convolutional neural networks (CNNs) based on task samples, using supervised and semi-supervised learning. On the other hand, Learning to Learn for Policy Learning involves meta-learning, which aims to develop a policy that can adapt to any new task within a given task distribution. In the meta-training or meta-testing process, previous meta-reinforcement learning (meta-RL) methods rely on rewards for policy adaptation.
Researchers from the University of Maryland, Tsinghua University, University of California, Shanghai Qi Zhi Institute, and Shanghai AI Lab have proposed Make-An-Agent, a new method for generating policies using conditional diffusion models. In this process, an autoencoder is developed to compress policy networks into smaller latent representations based on their layer. Researchers used contrastive learning to get the connection between long-term trajectories and their outcomes or future states. Further, an effective diffusion model is utilized based on learned behavior embeddings to generate policy parameters, which are then decoded into usable policies with the pre-trained decoder.
The performance of Make-An-Agent is evaluated by testing in three continuous control domains, including various tabletop manipulation and real-world locomotion tasks. The policies were generated during the testing phase using trajectories from the replay buffer of partially trained RL agents. Generated policies outperformed those created by multi-task or meta-learning and other hypernetwork-based methods. This approach has the potential to produce diverse policy parameters and show strong performance despite environmental randomness in both simulators and real-world situations. Moreover, Make-An-Agent can produce high-performing policies even when given noisy trajectories, demonstrating the robustness of the model.
The policies generated by the Make-An-Agent in real-world scenarios are tested using a technique, walk-these-ways and trained on IsaacGym. Actor networks are generated using the proposed method based on trajectories from IsaacGym simulations and pre-trained adaptation modules. These generated policies are then deployed on real robots in environments different from the simulations. Each policy for real-world movement includes 50,956 parameters, and 1,500 policy networks are collected for each task in MetaWorld and Robosuite. These networks come from policy checkpoints during SAC training and are saved every 5,000 training steps after the test success rate hits 1.
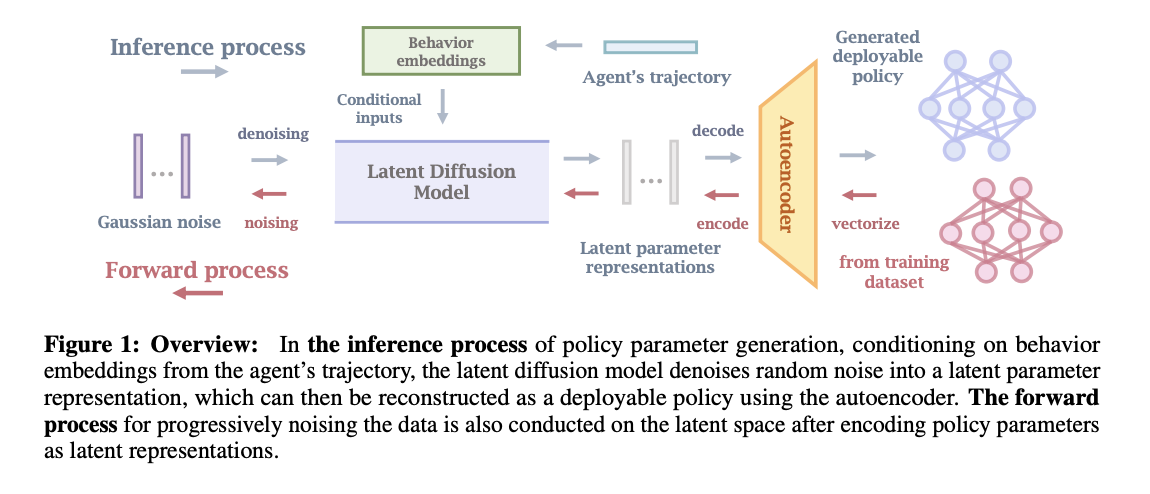
In this paper, researchers present a new policy generation method called Make-An-Agent, based on conditional diffusion models. This method aims to generate policies in spaces with many parameters using an autoencoder to encode and reconstruct these parameters. The results, tested across various domains, show that their approach works well in multi-task settings, can handle new tasks, and is resistant to environmental randomness. However, due to a large number of parameters, more diverse policy networks are not explored, and the abilities of the parameter diffusion generator are limited by the parameter autoencoder, so, future research could look into more flexible ways of generating parameters.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post Make-An-Agent: A Novel Policy Parameter Generator that Leverages the Power of Conditional Diffusion Models for Behavior-to-Policy Generation appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #Staff #TechNews #Technology [Source: AI Techpark]