


Large language models (LLMs) such as GPT-3 and Llama-2 have made significant strides in understanding and generating human language. These models boast billions of parameters, allowing them to perform complex tasks accurately. However, the substantial computational resources required for training and deploying these models present significant challenges, particularly in resource-limited environments. Addressing these challenges is essential to making AI technologies more accessible and broadly applicable.
The primary issue with deploying large language models is their immense size and the corresponding need for extensive computational power and memory. This limitation significantly restricts their usability in scenarios where computational resources are constrained. Traditionally, multiple versions of the same model are trained to balance efficiency and accuracy based on the available resources. For example, the Llama-2 model family includes variants with 7 billion, 13 billion, and 70 billion parameters. Each variant is designed to operate efficiently within different levels of computational power. However, this approach is resource-intensive, requiring significant effort and computational resource duplication.
Existing methods to address this issue include training several versions of a model, each tailored for different resource constraints. While effective in providing flexibility, this strategy involves considerable redundancy in the training process, consuming time and computational resources. For instance, training multiple multi-billion parameter models, like those in the Llama-2 family, demands substantial data and computational power, making the process impractical for many applications. To streamline this, researchers have been exploring more efficient alternatives.
Researchers from NVIDIA and the University of Texas at Austin introduced FLEXTRON, a novel flexible model architecture and post-training optimization framework. FLEXTRON is designed to support adaptable model deployment without requiring additional fine-tuning, thus addressing the inefficiencies of traditional methods. This architecture employs a nested elastic structure, allowing it to adjust dynamically to specific latency and accuracy targets during inference. This adaptability makes using a single pre-trained model across various deployment scenarios possible, significantly reducing the need for multiple model variants.
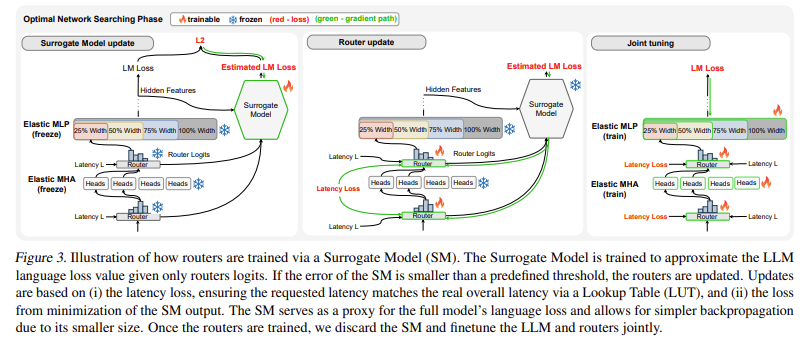
FLEXTRON transforms a pre-trained LLM into an elastic model through a sample-efficient training method and advanced routing algorithms. The transformation process includes ranking and grouping network components and training routers that manage sub-network selection based on user-defined constraints such as latency and accuracy. This innovative approach enables the model to automatically select the optimal sub-network during inference, ensuring efficient and accurate performance across different computational environments.
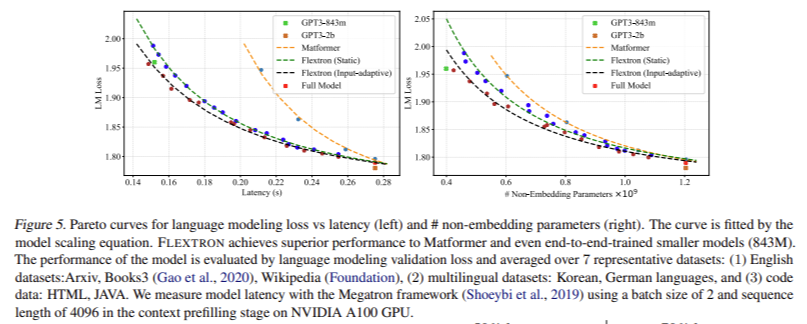
Performance evaluations of FLEXTRON demonstrated its superior efficiency and accuracy compared to multiple end-to-end trained models and other state-of-the-art elastic networks. For example, FLEXTRON performed remarkably on the GPT-3 and Llama-2 model families, requiring only 7.63% of the training tokens used in the original pre-training. This efficiency translates into significant savings in computational resources and time. The evaluation included various benchmarks, such as ARC-easy, LAMBADA, PIQA, WinoGrande, MMLU, and HellaSwag, where FLEXTRON consistently outperformed other models.
The FLEXTRON framework also includes an elastic Multi-Layer Perceptron (MLP) and elastic Multi-Head Attention (MHA) layers, enhancing its adaptability. Elastic MHA layers, which constitute a significant portion of LLM runtime and memory usage, improve overall efficiency by selecting a subset of attention heads based on the input data. This feature is particularly beneficial in scenarios with limited computational resources, as it allows more efficient use of available memory and processing power.

In conclusion, FLEXTRON, offering a flexible and adaptable architecture that optimizes resource use and performance, addresses the critical need for efficient model deployment in diverse computational environments. The introduction of this framework by researchers from NVIDIA and the University of Texas at Austin highlights the potential for innovative solutions in overcoming the challenges associated with large language models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post NVIDIA Researchers Introduce Flextron: A Network Architecture and Post-Training Model Optimization Framework Supporting Flexible AI Model Deployment appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]