


Large language models (LLMs) have gained significant attention in solving planning problems, but current methodologies must be revised. Direct plan generation using LLMs has shown limited success, with GPT-4 achieving only 35% accuracy on simple planning tasks. This low accuracy highlights the need for more effective approaches. Another significant challenge lies in the lack of rigorous techniques and benchmarks for evaluating the translation of natural language planning descriptions into structured planning languages, such as the Planning Domain Definition Language (PDDL).
Researchers have explored various approaches to overcome the challenges of using LLMs for planning tasks. One method involves using LLMs to generate plans directly, but this has shown limited success due to poor performance even on simple planning tasks. Another approach, “Planner-Augmented LLMs,” combines LLMs with classical planning techniques. This method frames the problem as a machine translation task, converting natural language descriptions of planning problems into structured formats like PDDL, finite state automata, or logic programming.
The hybrid approach of translating natural language to PDDL utilizes the strengths of both LLMs and traditional symbolic planners. LLMs interpret natural language, while efficient traditional planners ensure solution correctness. However, evaluating code generation tasks, including PDDL translation, remains challenging. Existing evaluation methods, such as match-based metrics and plan validators, need to be revised in assessing the accuracy and relevance of generated PDDL to the original instructions.
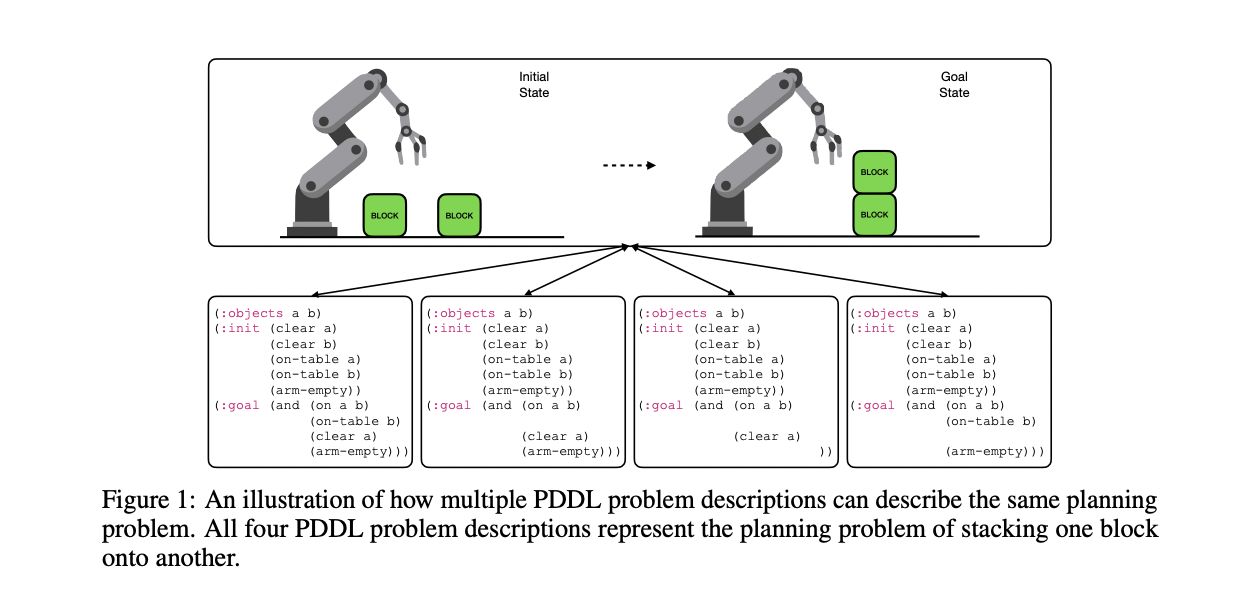
Researchers from the Department of Computer Science at Brown University present Planetarium, a rigorous benchmark for evaluating LLMs’ ability to translate natural language descriptions of planning problems into PDDL, addressing the challenges in assessing PDDL generation accuracy. This benchmark offers a rigorous approach to evaluating PDDL equivalence, formally defining planning problem equivalence and providing an algorithm to check whether two PDDL problems satisfy this definition. Planetarium includes a comprehensive dataset featuring 132,037 ground truth PDDL problems with corresponding text descriptions, varying in abstraction and size. The benchmark also provides a broad evaluation of current LLMs in both zero-shot and fine-tuned settings, revealing the task’s difficulty. With GPT-4 achieving only 35.1% accuracy in a zero-shot setting, Planetarium serves as a valuable tool for measuring progress in LLM-based PDDL generation and is publicly available for future development and evaluation.
The Planetarium benchmark introduces a rigorous algorithm for evaluating PDDL equivalence, addressing the challenge of comparing different representations of the same planning problem. This algorithm transforms PDDL code into scene graphs, representing both initial and goal states. It then fully specifies the goal scenes by adding all trivially true edges and creates problem graphs by joining initial and goal scene graphs.
The equivalence check involves several steps: First, it performs quick checks for obvious non-equivalence or equivalence cases. If these fail, it proceeds to fully specify the goal scenes, identifying all propositions true in all reachable goal states. The algorithm then operates in two modes: one for problems where object identity matters, and another where objects in goal states are treated as placeholders. For problems with object identity, it checks isomorphism between combined problem graphs. For placeholder problems, it checks isomorphism between initial and goal scenes separately. This approach ensures a comprehensive and accurate evaluation of PDDL equivalence, capable of handling various representation nuances in planning problems.

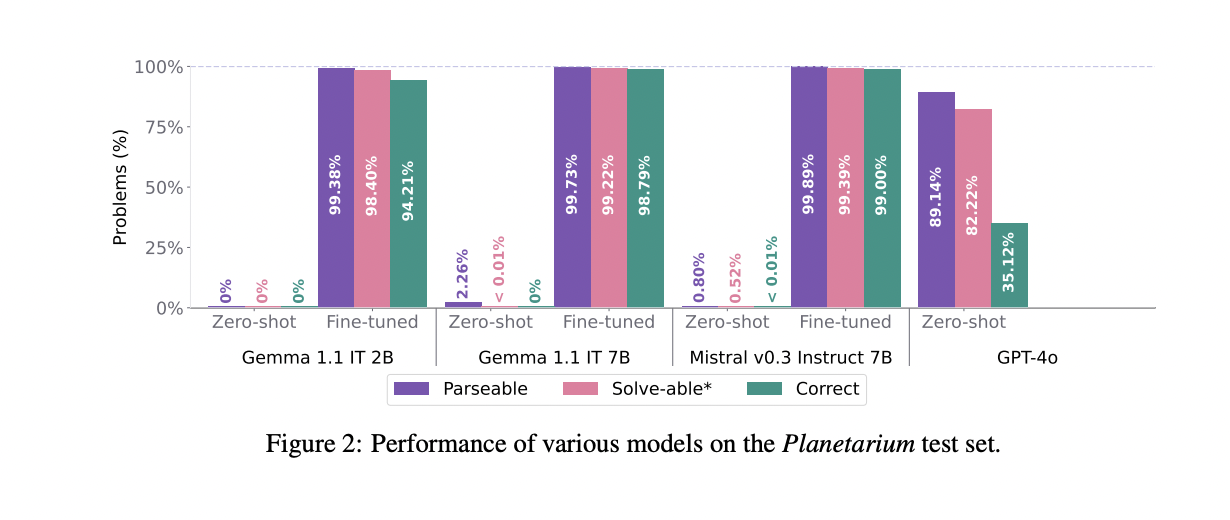
The Planetarium benchmark evaluates the performance of various large language models (LLMs) in translating natural language descriptions into PDDL. Results show that GPT-4o, Mistral v0.3 7B Instruct, and Gemma 1.1 IT 2B & 7B all performed poorly in zero-shot settings, with GPT-4o achieving the highest accuracy at 35.12%. GPT-4o’s performance breakdown reveals that abstract task descriptions are more challenging to translate than explicit ones, while fully explicit task descriptions facilitate the easier generation of parseable PDDL codeThey is also so, Fine-tuning significantly improved performance across all open-weight models. Mistral v0.3 7B Instruct achieved the highest accuracy after fine-tuning.
This study introduces the Planetarium benchmark which marks a significant advance in evaluating LLMs’ ability to translate natural language into PDDL for planning tasks. It addresses crucial technical and societal challenges, emphasizing the importance of accurate translations to prevent potential harm from misaligned results. Current performance levels, even for advanced models like GPT-4, highlight the complexity of this task and the need for further innovation. As LLM-based planning systems evolve, Planetarium provides a vital framework for measuring progress and ensuring reliability. This research pushes the boundaries of AI capabilities and underscores the importance of responsible development in creating trustworthy AI planning systems.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post Planetarium: A New Benchmark to Evaluate LLMs on Translating Natural Language Descriptions of Planning Problems into Planning Domain Definition Language PDDL appeared first on MarkTechPost.
#AIGovernance #AIPaperSummary #AIShorts #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]