


Large Language Models (LLMs) have demonstrated remarkable proficiency in language generation tasks. However, their training process, which involves unsupervised learning from extensive datasets followed by supervised fine-tuning, presents significant challenges. The primary concern stems from the nature of pre-training datasets, such as Common Crawl, which often contain undesirable content. Consequently, LLMs inadvertently acquire the ability to generate offensive language and potentially harmful advice. This unintended capability poses a serious safety risk, as these models can produce coherent responses to user inputs without proper content filtering. The challenge for researchers lies in developing methods to maintain the LLMs’ language generation capabilities while effectively mitigating the production of unsafe or unethical content.
Existing attempts to overcome the safety concerns in LLMs have primarily focused on two approaches: safety tuning and the implementation of guardrails. Safety tuning aims to optimize models to respond in a manner aligned with human values and safety considerations. However, these chat models remain vulnerable to jailbreak attacks, which employ various strategies to circumvent safety measures. These strategies include using low-resource languages, refusal suppression, privilege escalation, and distractions.
To counter these vulnerabilities, researchers have developed guardrails to monitor exchanges between chat models and users. One notable approach involves the use of model-based guardrails, which are separate from the chat models themselves. These guard models are designed to flag harmful content and serve as a critical component of AI safety stacks in deployed systems.
However, the current methods face significant challenges. The use of separate guard models introduces substantial computational overhead, making them impractical in low-resource settings. Also, the learning process is inefficient due to the considerable overlap in language understanding abilities between chat models and guard models, as both need to perform their respective tasks of response generation and content moderation effectively.
Samsung R&D Institute researchers present LoRA-Guard, an innovative system that integrates chat and guard models, addressing efficiency issues in LLM safety. It uses a low-rank adapter on a chat model’s transformer backbone to detect harmful content. The system operates in dual modes: activating LoRA parameters for guardrailing with a classification head, and deactivating them for normal chat functions. This approach significantly reduces parameter overhead by 100-1000x compared to previous methods, making deployment feasible in resource-constrained settings. LoRA-Guard has been evaluated on various datasets, including zero-shot scenarios, and its model weights have been published to support further research.
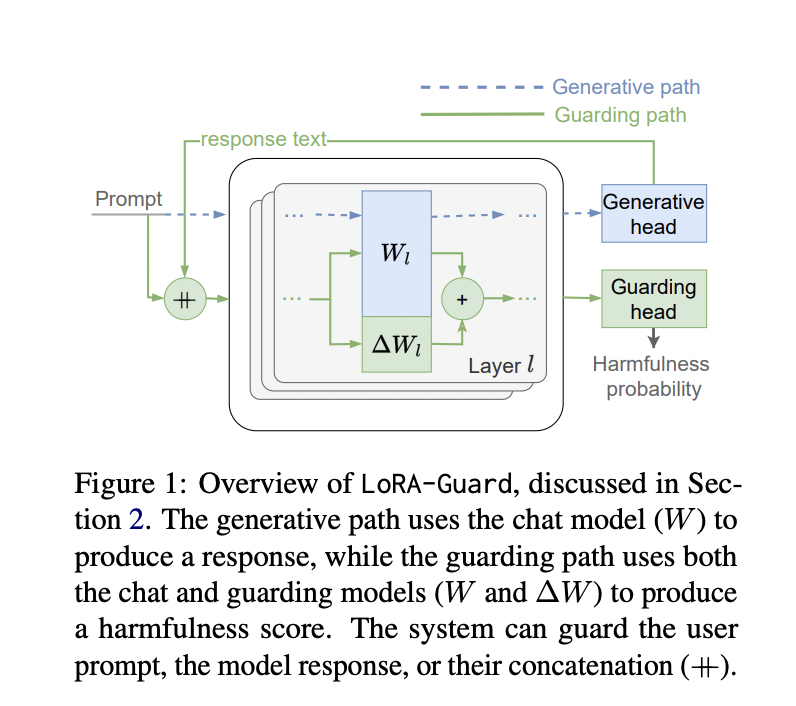
LoRA-Guard’s architecture is designed to efficiently integrate guarding capabilities into a chat model. It uses the same embedding and tokenizer for both the chat model C and the guard model G. The key innovation lies in the feature map: while C uses the original feature map f, G employs f’ with LoRA adapters attached to f. G also utilizes a separate output head hguard for classification into harmfulness categories.
This dual-path design allows for seamless switching between chat and guard functions. By activating or deactivating LoRA adapters and switching between output heads, the system can perform either task without performance degradation. The parameter sharing between paths significantly reduces the computational overhead, with the guard model typically adding only a fraction (often 1/1000th) of the original model’s parameters.
LoRA-Guard is trained through supervised fine-tuning of f’ and hguard on labeled datasets, keeping the chat model’s parameters frozen. This approach utilizes the chat model’s existing knowledge while learning to detect harmful content efficiently.
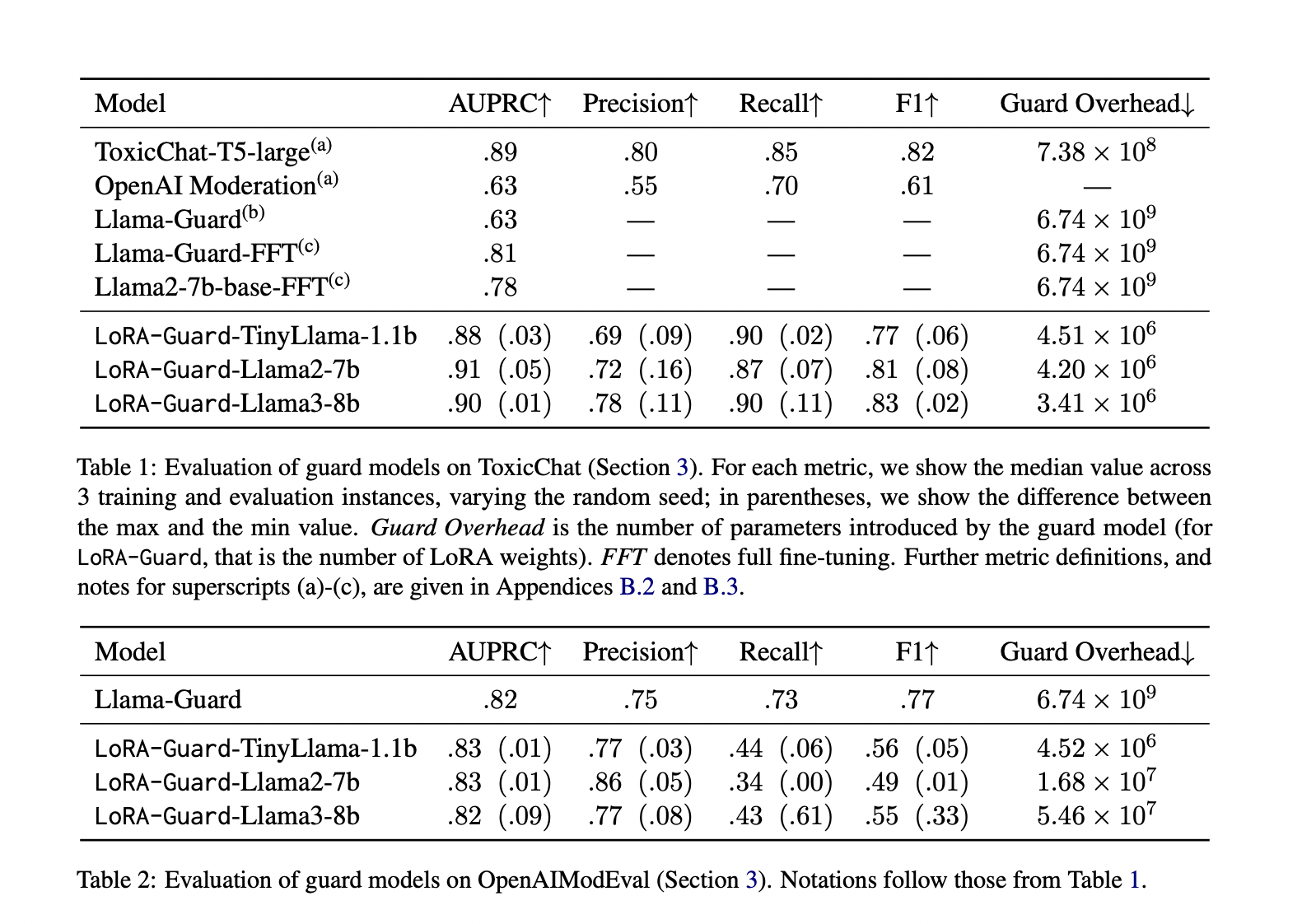
LoRA-Guard demonstrates exceptional performance on multiple datasets. On ToxicChat, it outperforms baselines in AUPRC while using significantly fewer parameters – up to 1500 times less than fully fine-tuned models. For OpenAIModEval, it matches alternative methods with 100 times fewer parameters. Cross-domain evaluations reveal interesting asymmetries: models trained on ToxicChat generalize well to OpenAIModEval, but the reverse shows considerable performance drops. This asymmetry might be due to differences in dataset characteristics or the presence of jailbreak samples in ToxicChat. Overall, LoRA-Guard proves to be an efficient and effective solution for content moderation in language models.
LoRA-Guard represents a significant leap in moderated conversational systems, reducing guardrailing parameter overhead by 100-1000 times while maintaining or improving performance. This efficiency is achieved through knowledge sharing and parameter-efficient learning mechanisms. Its dual-path design prevents catastrophic forgetting during fine-tuning, a common issue in other approaches. By dramatically reducing training time, inference time, and memory requirements, LoRA-Guard emerges as a crucial development for implementing robust content moderation in resource-constrained environments. As on-device LLMs become more prevalent, LoRA-Guard paves the way for safer AI interactions across a broader range of applications and devices.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post Samsung Researchers Introduce LoRA-Guard: A Parameter-Efficient Guardrail Adaptation Method that Relies on Knowledge Sharing between LLMs and Guardrail Models appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]