


Language model adaptation is a crucial area in artificial intelligence, focusing on enhancing large pre-trained language models to work effectively across various languages. This research is vital for enabling these models to understand and generate text in multiple languages, which is essential for global AI applications. Despite the impressive performance of LLMs in English, their capabilities significantly drop when adapted to less prevalent languages, making additional adaptation techniques necessary.
One of the significant challenges in adapting language models to new languages is catastrophic forgetting. This occurs when a model loses its proficiency in the original language while learning a new one, severely limiting its usefulness. Retaining the base model’s capabilities is essential for solving tasks in the new language, as skills such as math and coding learned in English are invaluable for problem-solving and reasoning in other languages.
Current methods to address catastrophic forgetting include continued pretraining and instruction tuning with experience replay. Experience replay involves mixing data from the original language during training in the new language. However, this approach needs to be revised to fully mitigate forgetting, especially when the exact source data is unknown. The approximation of experience replay reduces its effectiveness, necessitating further regularization to maintain the model’s performance in the base language.
Researchers from INSAIT, LogicStar.ai, ETH Zurich, the University of Chicago, and Together AI introduced a novel approach called Branch-and-Merge (BAM). This method iteratively merges multiple models, each fine-tuned on different subsets of training data, to achieve lower magnitude but higher quality weight changes. By combining these models, BAM reduces forgetting while maintaining learning efficiency. The BAM method splits the training data into several slices and fine-tunes the base model on these slices in parallel. The resulting models are merged to form a new base model for the next iteration. This iterative process minimizes the total weight change, reducing the risk of catastrophic forgetting. Additionally, by leveraging multiple training slices, BAM ensures the retention of essential skills from the base language.
In detail, BAM splits the training data into N slices and fine-tunes the base model on K (typically two) of these slices in parallel before merging the resulting models. This significantly reduces the total weight change, preserving most of the learning from the parallel training steps. The research team applied BAM to adapt models like MISTRAL-7B and LLAMA-3-8B from predominantly English to Bulgarian and German. They found that BAM consistently improved benchmark performance in target and source languages compared to standard training methods. For instance, the BAM-trained LLAMA-3-8B improved Bulgarian task performance by 10.9% and English task performance by 1.3%, demonstrating the method’s efficacy.
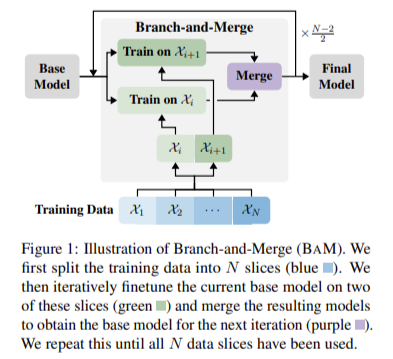
To further understand the performance of BAM, the researchers conducted an extensive empirical study. They applied BAM to adapt MISTRAL-7B and LLAMA-3-8B models, predominantly using English data, to Bulgarian and German languages. The results showed that BAM significantly reduced forgetting while matching or improving target domain performance compared to standard continued pretraining and fine-tuning instruction. Specifically, BAM allowed the LLAMA-3-8B model to outperform its standard counterpart by 10.9% in Bulgarian tasks and 1.3% in English tasks. This improvement is attributed to the smaller magnitude but more efficient weight changes induced by BAM.
BAM was evaluated using both approximate and minimal experience replay. The approximate experience replay involved a mix of 15.1 billion unique tokens from sources like OpenWebText, English Wikipedia, and GitHub repositories. In contrast, minimal experience replay used only 5 billion tokens from OpenWebText for German and 10 billion tokens for Bulgarian. The study found that approximate experience replay led to a stronger increase in target domain performance and reduced forgetting of the source domain compared to minimal experience replay.

The effectiveness of BAM was also demonstrated in instruction fine-tuning. Using 928,000 samples of English finetuning data mixed with German or Bulgarian data, BAM slightly improved learning in both target languages while significantly reducing forgetting. For instance, BAM-trained models outperformed the standard instruction fine-tuning models in the Bulgarian instruction tuning, achieving 10.8% better performance in Bulgarian tasks and 1.3% better in English tasks.

In conclusion, the Branch-and-Merge (BAM) method offers a robust solution for catastrophic forgetting in language model adaptation. Ensuring minimal yet effective weight changes preserves the model’s capabilities in the original language while enhancing its performance in the target language. This approach can significantly benefit practitioners working on multilingual AI applications, providing a more efficient way to adapt large language models to diverse linguistic environments. The research demonstrated that BAM could effectively balance learning and forgetting, making it a valuable method for continuous pretraining and instruction tuning in alphabet- and non-alphabet-sharing languages.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post Branch-and-Merge Method: Enhancing Language Adaptation in AI Models by Mitigating Catastrophic Forgetting and Ensuring Retention of Base Language Capabilities while Learning New Languages appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]