


Evaluating the performance of large language model (LLM) inference systems using conventional metrics presents significant challenges. Metrics such as Time To First Token (TTFT) and Time Between Tokens (TBT) do not capture the complete user experience during real-time interactions. This gap is critical in applications like chat and translation, where responsiveness directly affects user satisfaction. There is a need for a more nuanced evaluation framework that fully encapsulates the intricacies of LLM inference to ensure optimal deployment and performance in real-world scenarios.
Current methods for evaluating LLM inference performance include TTFT, TBT, normalized latency, and Time Per Output Token (TPOT). These metrics assess various aspects of latency and throughput but fall short in providing a comprehensive view of the user experience. For example, TTFT and TBT focus on individual token latencies without considering end-to-end throughput, while normalized metrics obscure issues like inter-token jitter and scheduling delays. These limitations hinder their effectiveness in real-time applications where maintaining a smooth and consistent token generation rate is crucial.
A team of researchers from Georgia Institute of Technology, Microsoft Research India, and Intel AI Lab propose Metron, a comprehensive performance evaluation framework. Metron introduces novel metrics such as the fluidity-index and fluid token generation rate, which capture the nuances of real-time, streaming LLM interactions. These metrics consider the temporal aspects of token generation, ensuring a more accurate reflection of user-facing performance. By setting token-level deadlines and measuring the fraction of deadlines met, the fluidity-index provides a precise definition of user experience constraints. This approach represents a significant contribution by offering a more accurate and user-centric evaluation method.
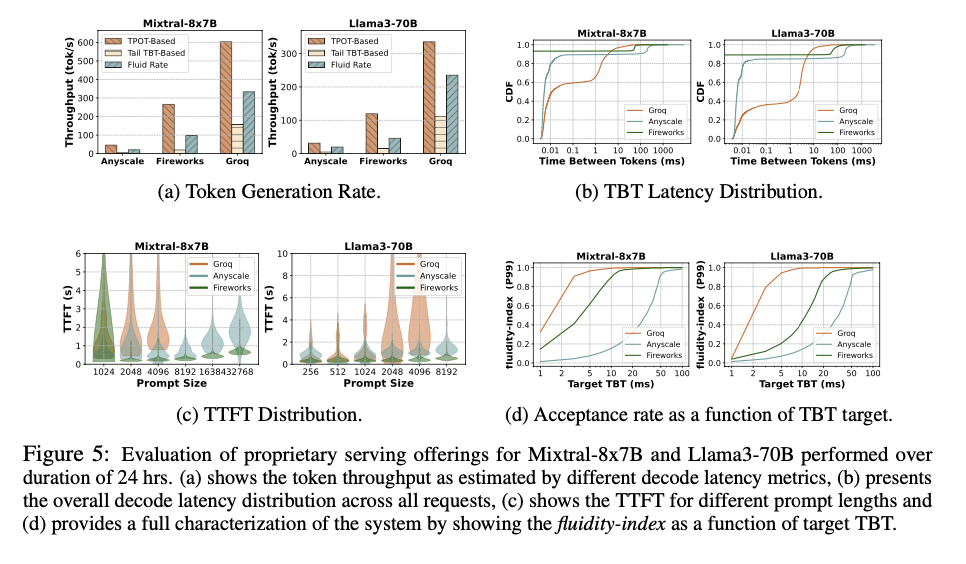
Metron’s fluidity-index metric sets deadlines for token generation based on desired TTFT and TBT values, adjusting these based on prompt length and observed system performance. This method accounts for scheduling delays and variable token generation rates, ensuring smooth output. The framework evaluates both open-source and proprietary LLM inference systems, applying the fluidity-index to measure the percentage of deadlines met and dynamically adjusting deadlines based on real-time performance. This method offers a comprehensive view of the system’s capacity to handle user requests without compromising responsiveness.
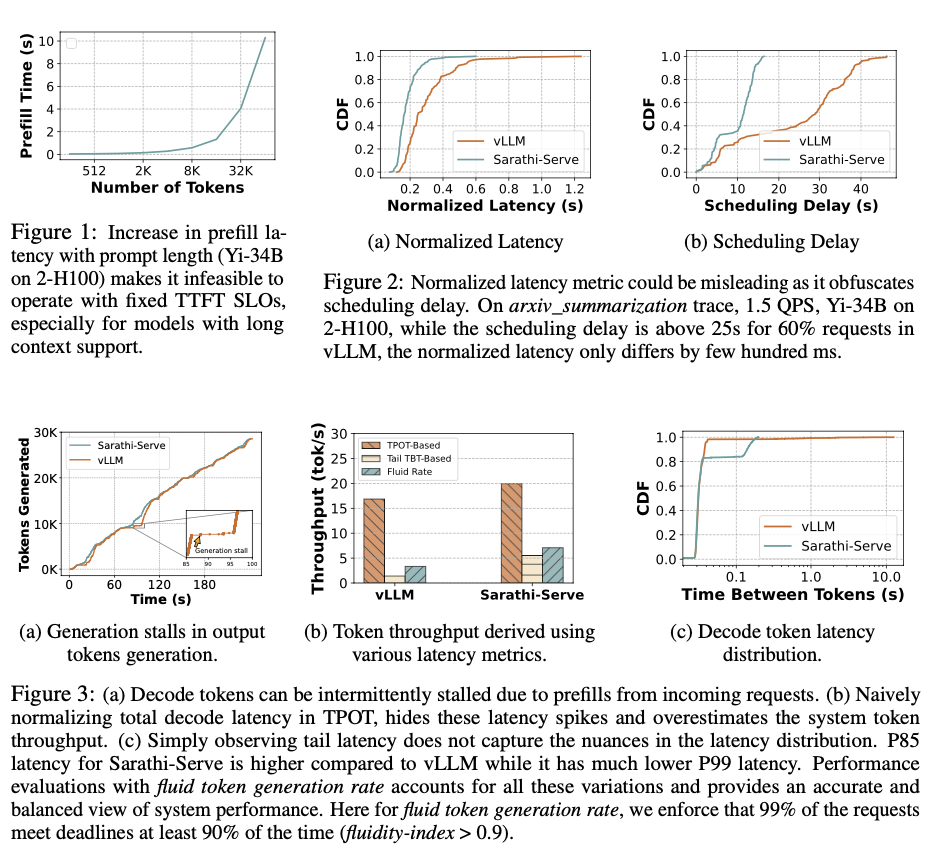
Metron provides a more accurate evaluation of LLM inference systems compared to conventional metrics. The fluidity-index and fluid token generation rate reveal significant differences in user experience that are not captured by TTFT or TBT alone. For example, the evaluation of systems like vLLM and Sarathi-Serve demonstrated that Sarathi-Serve achieved fewer deadline misses and higher fluidity. The findings show that Sarathi-Serve maintained a fluidity-index > 0.9 for 99% of requests, achieving a throughput of 600 tokens per second, while vLLM showed a 3x worse tail TBT due to generation stalls. This demonstrates Metron’s effectiveness in revealing performance differences and ensuring better user experiences in real-world applications.
In conclusion, this proposed method, Metron, introduces a novel evaluation framework, including the fluidity-index and fluid token generation rate metrics, to better assess LLM inference performance. This approach overcomes the limitations of conventional metrics by providing a user-centric evaluation that captures the intricacies of real-time token generation. The findings demonstrate Metron’s effectiveness in revealing performance differences and its potential impact on improving LLM serving frameworks, ensuring better user experiences in real-world applications.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post Metron: A Holistic AI Framework for Evaluating User-Facing Performance in LLM Inference Systems appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #DeepLearning #EditorsPick #LanguageModel #LargeLanguageModel #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]