


Large Language Models (LLMs) have become critical tools in various domains due to their exceptional ability to understand and generate human language. These models, which often contain billions of parameters, require extensive computational resources for training and fine-tuning. The primary challenge lies in efficiently managing the memory and computational demands to make these models accessible to various users & applications.
Training LLMs are inherently memory-intensive, necessitating substantial hardware resources that are only readily available to some users. Traditional methods demand large memory allocations to handle the numerous parameters and optimization states. For instance, training a LLaMA 7B model from scratch typically requires around 58 GB of memory, including 14 GB for trainable parameters, 42 GB for Adam optimizer states and weight gradients, and 2 GB for activation. This high memory requirement poses a significant barrier to entry for many researchers and developers who need access to advanced hardware setups.
Various techniques have been developed to address this problem. These include designing smaller-scale LLMs, employing efficient scaling techniques, and incorporating sparsity into the training methodologies. Among these, GaLore has emerged as a notable method, allowing for the full-parameter training of LLMs through low-rank gradient updates using Singular Value Decomposition (SVD). GaLore reduces memory usage by up to 63.3%, enabling training a 7B model with just 24GB of memory. However, GaLore still requires more memory than is available on many commonly used devices, such as popular laptop GPUs like the RTX 4060 Ti, which have up to 16GB of memory.
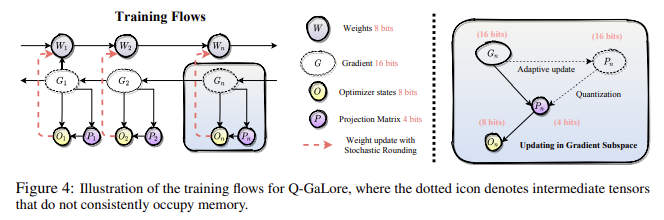
Researchers from the University of Texas at Austin, the University of Surrey, the University of Oxford, the California Institute of Technology, and Meta AI have introduced Q-GaLore to reduce memory consumption further and make LLM training more accessible. Q-GaLore combines quantization and low-rank projection to enhance memory efficiency significantly. This method builds on two key observations: the gradient subspace exhibits diverse properties, with some layers stabilizing early in training. In contrast, others change frequently, and the projection matrices are highly resilient to low-bit quantization. By leveraging these insights, Q-GaLore adaptively updates the gradient subspace based on convergence statistics, maintaining performance while reducing the number of SVD operations. The model weights are kept in INT8 format, and the projection matrices are in INT4 format, which conserves memory aggressively.
Q-GaLore employs two main modules: low-precision training with low-rank gradients and lazy layer-wise subspace exploration. The entire model, including optimizer states, uses 8-bit precision for the Adam optimizer, and the projection matrices are quantized to 4 bits. This approach results in a memory reduction of approximately 28.57% for gradient low-rank training. Stochastic rounding maintains training stability and approximates the high-precision training trajectory. This method allows for a high-precision training path using only low-precision weights, preserving small gradient contributions effectively without needing to maintain high-precision parameters.

In practical applications, Q-GaLore has performed exceptionally in pre-training and fine-tuning scenarios. During pre-training, Q-GaLore enabled the training of an LLaMA-7B model from scratch on a single NVIDIA RTX 4060 Ti with only 16GB of memory. This is a significant achievement, demonstrating the method’s exceptional memory efficiency and practicality. In fine-tuning tasks, Q-GaLore reduced memory consumption by up to 50% compared to other methods like LoRA and GaLore while consistently outperforming QLoRA by up to 5.19 on MMLU benchmarks at the same memory cost.
Q-GaLore’s performance and efficiency were evaluated across various model sizes, from 60 million to 7 billion parameters. For a 1 billion parameter model, Q-GaLore maintained comparable pre-training performance with less than a 0.84 increase in perplexity compared to the original GaLore method while achieving a 29.68% memory saving against GaLore and a 60.51% memory saving compared to the full baseline. Notably, Q-GaLore facilitated the pre-training of a 7B model within a 16GB memory constraint, achieving a perplexity difference of less than one compared to the baseline models.

In conclusion, Q-GaLore offers a practical solution to the memory constraints traditionally associated with these models in the efficient training of LLMs. By combining quantization and low-rank projection, Q-GaLore achieves competitive performance and broadens the accessibility of powerful language models. This method highlights the potential for optimizing large-scale models for more commonly available hardware configurations, making cutting-edge language processing technologies more accessible to a wider audience.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post Q-GaLore Released: A Memory-Efficient Training Approach for Pre-Training and Fine-Tuning Machine Learning Models appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #MachineLearning #Staff #TechNews #Technology #Uncategorized #FineTuning [Source: AI Techpark]