


Computer vision enables machines to interpret & understand visual information from the world. This encompasses a variety of tasks, such as image classification, object detection, and semantic segmentation. Innovations in this area have been propelled by developing advanced neural network architectures, particularly Convolutional Neural Networks (CNNs) and, more recently, Transformers. These models have demonstrated significant potential in processing visual data. Still, there remains a continuous need for improvements in their ability to balance computational efficiency with capturing both local and global visual contexts.
A central challenge in computer vision is the efficient modeling and processing of visual data. This requires understanding both local details and broader contextual information within images. Traditional models often need help with this balance. CNNs, while efficient at handling local spatial relationships, may overlook broader contextual information. On the other hand, Transformers, which leverage self-attention mechanisms to capture global context, can be computationally intensive due to their quadratic complexity relative to sequence length. This trade-off between efficiency and context-capture capability has significantly hindered the advancing vision models’ performance.
Existing approaches primarily utilize CNNs for their effectiveness in handling local spatial relationships. However, these models may only partially capture the broader contextual information necessary for more complex vision tasks. Transformers have been applied to vision tasks to address this issue, utilizing self-attention mechanisms to enhance the understanding of the global context. Despite these advancements, both CNNs and Transformers have inherent limitations. CNNs can miss the broader context, while Transformers are computationally expensive and challenging to train and deploy efficiently.
Researchers at NVIDIA have introduced MambaVision, a novel hybrid model that combines the strengths of Mamba and Transformer architectures. This new approach integrates CNN-based layers with Transformer blocks to enhance the modeling capacity for vision applications. The MambaVision family includes various model configurations to meet different design criteria and application needs, providing a flexible and powerful tool for various vision tasks. The introduction of MambaVision represents a significant step forward in the development of hybrid models for computer vision.
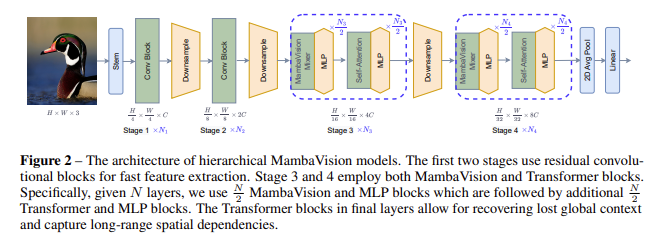
MambaVision employs a hierarchical architecture divided into four stages. The initial stages use CNN layers for rapid feature extraction, capitalizing on their efficiency in processing high-resolution features. The later stages incorporate MambaVision and Transformer blocks to effectively capture both short—and long-range dependencies. This innovative design allows the model to handle global context more efficiently than traditional approaches. The redesigned Mamba blocks, which now include self-attention mechanisms, are central to this improvement, enabling the model to process visual data with greater accuracy and throughput.
The performance of MambaVision is notable, achieving state-of-the-art results on the ImageNet-1K dataset. For example, the MambaVision-B model achieves a Top-1 accuracy of 84.2%, surpassing other leading models such as ConvNeXt-B and Swin-B, which gained 83.8% and 83.5%, respectively. In addition to its high accuracy, MambaVision demonstrates superior image throughput, with the MambaVision-B model processing images significantly faster than its competitors. In downstream tasks like object detection and semantic segmentation on the MS COCO and ADE20K datasets, MambaVision outperforms comparably-sized backbones, showcasing its versatility and efficiency. For instance, MambaVision models show improvements in box AP and mask AP metrics, achieving 46.4 and 41.8, respectively, higher than those achieved by models like ConvNeXt-T and Swin-T.
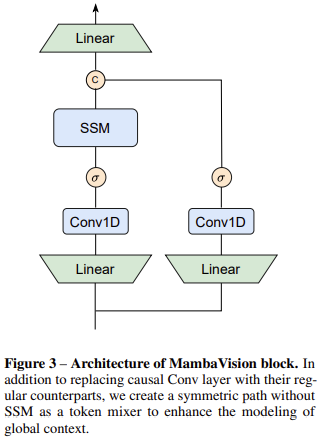
A comprehensive ablation study supports these findings, demonstrating the effectiveness of MambaVision’s design choices. The researchers improved accuracy and image throughput by redesigning the Mamba block to be more suitable for vision tasks. The study explored various integration patterns of Mamba and Transformer blocks, revealing that incorporating self-attention blocks in the final layers significantly enhances the model’s ability to capture global context and long-range spatial dependencies. This design produces a richer feature representation and better performance across various vision tasks.

In conclusion, MambaVision represents a significant advancement in vision modeling by combining the strengths of CNNs and Transformers into a single, hybrid architecture. This approach effectively addresses the limitations of existing models by enhancing understanding of local and global contexts, leading to superior performance in various vision tasks. The results of this study indicate a promising direction for future developments in computer vision, potentially setting a new standard for hybrid vision models.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post NVIDIA Researchers Introduce MambaVision: A Novel Hybrid Mamba-Transformer Backbone Specifically Tailored for Vision Applications appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #ComputerVision #EditorsPick #Staff #TechNews #Technology [Source: AI Techpark]