


Recent progress in Large Multimodal Models (LMMs) has demonstrated remarkable capabilities in various multimodal settings, moving closer to the goal of artificial general intelligence. By using large amounts of vision-language data, they enhance LLMs with visual abilities, by aligning vision encoders. However, most open-source LMMs have focused mainly on single-image scenarios, leaving the more complex multi-image scenarios mostly unexplored. This is important because many real-world applications use multi-image capabilities such as thorough multi-image analyses. Given the wide range of computer vision situations and data types, there is a strong need to develop a general framework for LMMs that can work effectively with multi-image, video, and 3D data.
To address these issues, this paper discusses some related works. The first work is Interleaved Image-text data, which gives LMMs two key abilities: multimodal in-context learning (ICL) and instruction-following in real-world multi-image scenarios. Next, Interleaved LMMs, like the closed-source GPT-4V and Gemini, support real-world multi-image applications with top performance. The community has also created open-source LMMs with excellent multi-image skills using diverse public datasets. In the last related work, interleaved benchmarks, several high-quality benchmarks have been developed for various scenarios to evaluate these multi-image abilities of LMMs.
Researchers from ByteDance, HKUST, CUHK, and NTU have proposed LLaVA-NeXT-Interleave, a versatile LMM that can handle various real-world settings such as Multi-image, Multi-frame (videos), Multi-view (3D) while maintaining the performance of the Multi-patch (single-image) performance. These four settings are collectively called M4. A high-quality training dataset, M4-Instruct, with 1177.6 samples is created to enhance LMMs with the M4 capabilities. This dataset covers 14 tasks and 41 datasets across these four domains. Using a single model, LLaVA-NeXT-Interleave shows top results in different multi-image tasks compared to previous state-of-the-art models, while still performing well with single images.
The LLaVA-NeXT-Interleave model is tested on M4. The LLaVA-Interleave Bench is selected to cover a range of in- and out-of-domain tasks while evaluating multi-image. For video evaluation, the tests include NExTQA, MVBench, Video Detailed Description (VDD), and ActivityNet-QA (Act). The results for ActivityNet-QA include both accuracy and GPT scores. Additionally, the model is assessed on VideoChat-GPT (VCG) using five criteria: correctness of information, detail orientation, context understanding, temporal understanding, and consistency. For 3D evaluation, the tests include ScanQA and two tasks from 3D-LLM.
The results for multi-image show that the average performance of LLaVA-NeXT-Interleave is better than earlier open-source models in in- and out-domain tests. After adding DPO, the proposed 7B model achieves top performance on the VDD and VideoChatGPT tests, outperforming the previous LLaVA-NeXTVideo (34B). The LLaVA-NeXT-Interleave only uses multi-view images to understand the 3D world and gets much higher scores in difficult 3D situations compared to 3D-LLM and Point-LLM. For single-image tasks, 307k (40%) of the original LLaVA-NeXT single-image data is added to the Multi-patch (single-image), making the model capable of handling these tasks.
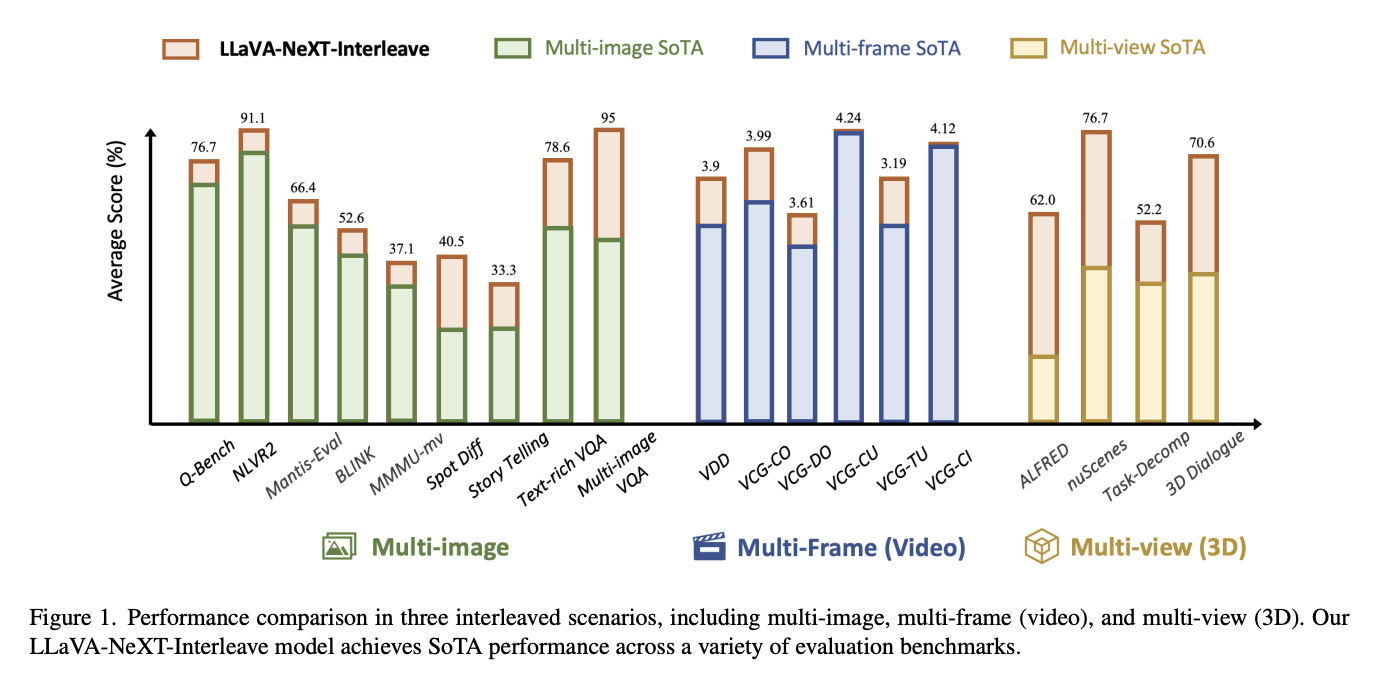
In conclusion, researchers have introduced LLaVA-NeXT-Interleave, a flexible LLM that can handle different real-world settings like multi-image, multi-frame (videos), and multi-view (3D). Researchers emphasized the potential of this model to improve and combine the capabilities of LMMs in various visual tasks. Extensive Experiments in this paper show that LLaVA-NeXT-Interleave sets new high standards in multi-image tasks and performs very well in single-image tasks. This work sets a new standard in the field, opening the door for future advancements in multimodal AI and complex visual understanding tasks.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post LLaVA-NeXT-Interleave: A Versatile Large Multimodal Model LMM that can Handle Settings like Multi-image, Multi-frame, and Multi-view appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #ComputerVision #EditorsPick #Staff #TechNews #Technology [Source: AI Techpark]