


Large language models (LLMs) have been instrumental in various applications, such as chatbots, content creation, and data analysis, due to their capability to process vast amounts of textual data efficiently. The rapid advancement in AI technology has heightened the demand for high-quality training data, which is essential for effectively functioning and improving these models.
One of the significant challenges in AI development is ensuring that the synthetic data used to train these models is diverse and of high quality. Synthetic data generation often requires extensive human effort for curation and filtering to ensure it meets the necessary standards. Without this quality control, there is a substantial risk of model collapse, where the models degrade over time due to the lack of variety and quality in the training data. This can lead to ineffective learning outcomes and biased results, limiting the models’ applicability in real-world scenarios.
Generating synthetic data involves using powerful models, such as GPT-4, to create responses to a set of prompts. Although effective, this method still necessitates significant human intervention to ensure the data’s relevance and quality. Researchers have developed techniques like step-by-step instructions and complex prompting to improve the quality of the generated data. Despite these efforts, the process remains labor-intensive and prone to inconsistencies.
Researchers from Microsoft Research introduced a novel framework known as AgentInstruct to address these challenges. This agentic framework automates the creation of diverse and high-quality synthetic data using raw data sources like text documents and code files as seeds. By leveraging advanced models and tools, AgentInstruct significantly reduces the need for human curation, streamlining the data generation process and enhancing the overall quality and diversity of the training data.
AgentInstruct employs a multi-agent workflow comprising content transformation, instruction generation, and refinement flows. This structured approach allows the framework to autonomously produce a wide variety of data, ensuring the generated content is complex and diverse. The system can create prompts and responses using powerful models and tools like search APIs and code interpreters. This method ensures high-quality data and introduces significant variety, which is crucial for comprehensive training.
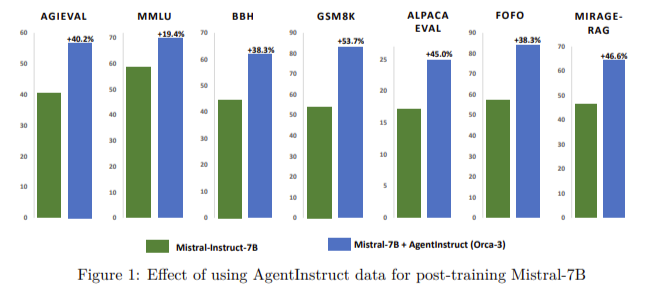
The researchers demonstrated the efficacy of AgentInstruct by creating a synthetic post-training dataset of 25 million pairs to teach various skills to language models. These skills included text editing, creative writing, tool usage, coding, and reading comprehension. The dataset was used to post-train a model called Orca-3, based on the Mistral-7b model. The results showed significant improvements across multiple benchmarks. For instance, Orca-3 exhibited a 40% improvement on AGIEval, a 19% improvement on MMLU, a 54% improvement on GSM8K, a 38% improvement on BBH, and a 45% improvement on AlpacaEval. Additionally, the model showed a 31.34% reduction in hallucinations across various summarization benchmarks, highlighting its enhanced accuracy and reliability.
The content transformation flow within AgentInstruct converts raw seed data into intermediate representations that simplify the creation of specific instructions. The seed instruction generation flow then takes these transformed seeds and generates diverse instructions following a comprehensive taxonomy. Finally, the instruction refinement flow iteratively enhances the complexity and quality of these instructions, ensuring the generated data’s robustness and applicability.
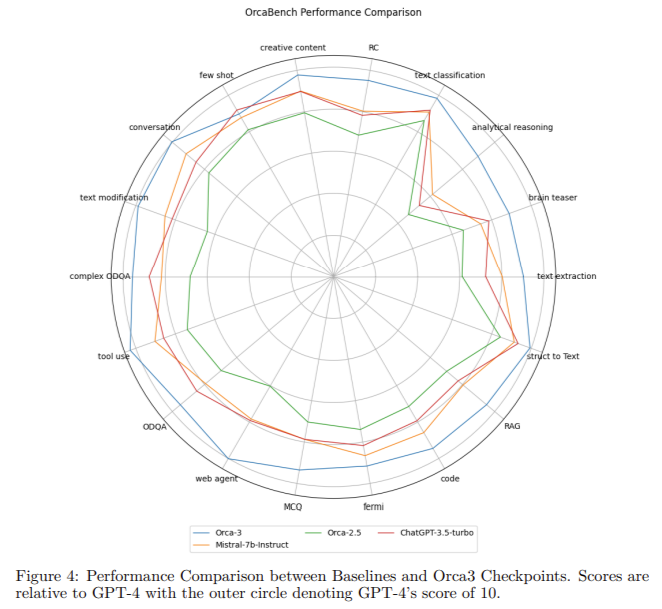
The performance of Orca-3, trained with the AgentInstruct dataset, significantly outperformed other instruction-tuned models using the same base model. It consistently showed better results than models such as LLAMA-8B-instruct and GPT-3.5-turbo. These benchmarks indicate the substantial advancements made possible by AgentInstruct in synthetic data generation.

In conclusion, AgentInstruct represents a breakthrough in generating synthetic data for AI training. Automating the creation of diverse and high-quality data addresses the critical issues of manual curation and data quality, leading to significant improvements in the performance and reliability of large language models. The substantial improvements observed in the Orca-3 model, such as the 40% improvement on AGIEval and the 54% improvement on GSM8K, underscore the effectiveness of this framework.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post Microsoft Research Introduces AgentInstruct: A Multi-Agent Workflow Framework for Enhancing Synthetic Data Quality and Diversity in AI Model Training appeared first on MarkTechPost.
#AIAgents #AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #MachineLearning #TechNews #Technology [Source: AI Techpark]