


Language modeling has significantly progressed in developing algorithms to understand, generate, and manipulate human language. These advancements have led to large language models that can perform translation, summarization, and question-answering tasks. These models are crucial for natural language processing (NLP) and artificial intelligence (AI) applications. However, these models face considerable challenges despite their capabilities, particularly in recalling information over extended contexts. This limitation is especially prominent in recurrent language models, which often need help efficiently storing and retrieving necessary information for accurate in-context learning. As a result, their performance needs to catch up to models with unrestricted memory.
Large language models, especially those based on Transformer architectures, have excelled in handling long-range dependencies in text through attention mechanisms. Transformers, however, demand substantial memory and computational resources, posing significant challenges. Recurrent neural networks (RNNs) and their variants offer a memory-efficient alternative but frequently compromise recall quality over long sequences. This recall issue is a critical obstacle in developing efficient and effective language models.
Researchers from Stanford University and the University at Buffalo introduced two innovative methods to address the above limitations of recurrent neural networks:
- JRT-Prompt
- JRT-RNN
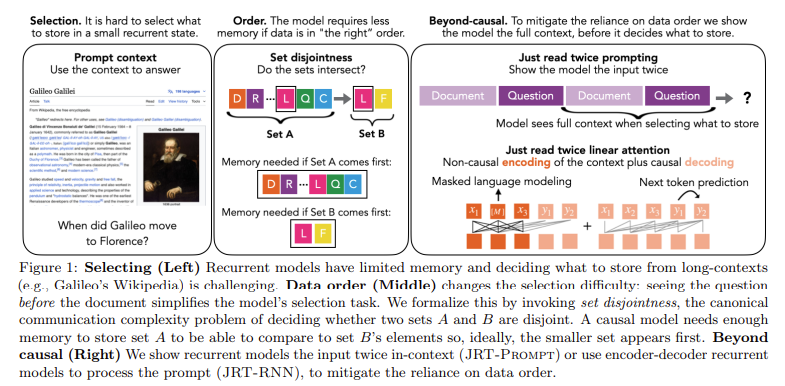
JRT-Prompt involves repeating the context in prompts to enhance recall, while JRT-RNN employs a non-causal recurrent architecture to improve context processing. These methods aim to mitigate the dependence on the order of data presentation, thereby enhancing the models’ ability to recall and utilize information efficiently.
JRT-Prompt improves recurrent models by repeating the input context multiple times and exposing the model to all data orders during training. This technique effectively reduces the reliance on the sequence in which data is presented. The model can better retain and recall information by delivering the context multiple times, improving its overall performance. In contrast, JRT-RNN utilizes prefix-linear attention, where the model processes the prompt non-causally before generating responses. This approach significantly enhances the model’s ability to recall and use information, providing a more efficient and effective solution to the recall problem in recurrent language models.
JRT-Prompt achieved an 11.0 ± 1.3 point improvement across various tasks and models, with 11.9 times higher throughput than the FlashAttention-2 for generation prefill (length 32k, batch size 16, NVidia H100). JRT-RNN provided up to a 13.7-point improvement in quality at 360 million parameters and a 6.9-point improvement at 1.3 billion parameters, along with 19.2 times higher throughput. These demonstrate that the proposed methods can match or exceed the performance of traditional Transformer models while using less memory.
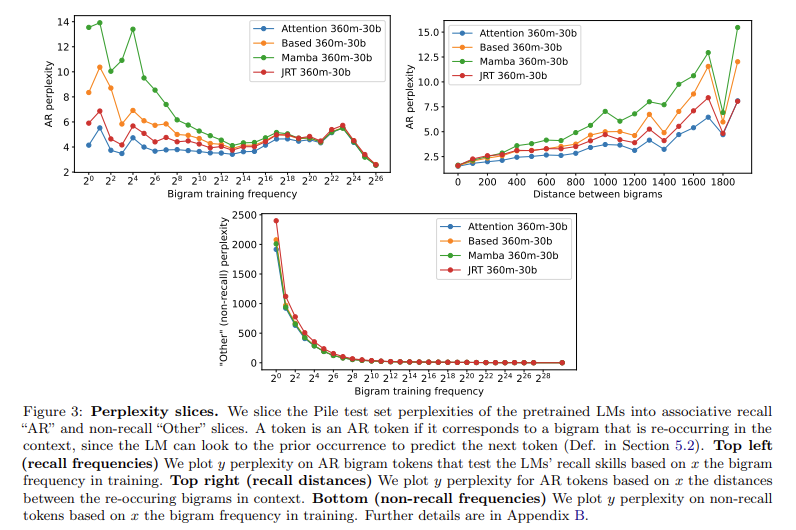
The effectiveness of JRT-Prompt and JRT-RNN was further validated through extensive empirical studies. JRT-Prompt was evaluated across 16 off-the-shelf recurrent LMs and six in-context learning tasks, consistently showing substantial improvements in recall quality. JRT-RNN, on the other hand, combined the strengths of recurrent and linear attention models, achieving 99% of Transformer quality at 360 million parameters with 30 billion tokens and 96% at 1.3 billion parameters with 50 billion tokens. This performance underscores the potential of these methods to provide efficient and high-quality language modeling solutions.

In conclusion, the research addresses the critical issue of information recall in recurrent language models and introduces effective methods to mitigate it. By improving data order handling and context processing, JRT-Prompt and JRT-RNN offer promising solutions that enhance the quality and efficiency of language models. These advancements represent a significant step toward developing more efficient and capable language modeling techniques. The proposed methods improve recall quality and significantly enhance computational efficiency, making them valuable tools.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post Researchers from Stanford and the University at Buffalo Introduce Innovative AI Methods to Enhance Recall Quality in Recurrent Language Models with JRT-Prompt and JRT-RNN appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]