


Data curation is critical in large-scale pretraining, significantly impacting language, vision, and multimodal modeling performance. Well-curated datasets can achieve strong performance with less data, but current pipelines often rely on manual curation, which is costly and hard to scale. Model-based data curation, leveraging training model features to select high-quality data, offers potential improvements in scaling efficiency. Traditional methods focus on individual data points, but batch quality also depends on composition. In computer vision, hard negatives—clusters of points with different labels—provide a more effective learning signal than easily solvable ones.
Researchers from Google DeepMind have shown that selecting batches of data jointly rather than independently enhances learning. Using multimodal contrastive objectives, they developed a simple JEST algorithm for joint example selection. This method selects relevant sub-batches from larger super-batches, significantly accelerating training and reducing computational overhead. By leveraging pretrained reference models, JEST guides the data selection process, improving performance with fewer iterations and less computation. Flexi-JEST, a variant of JEST, further reduces costs using variable patch sizing. This approach outperforms state-of-the-art models, demonstrating the effectiveness of model-based data curation.
Offline curation methods initially focused on the quality of textual captions and alignment with high-quality datasets, using pretrained models like CLIP and BLIP for filtering. These methods, however, fail to consider dependencies within batches. Cluster-level data pruning methods address this by reducing semantic redundancy and using core-set selection, but these are heuristic-based and decoupled from training objectives. Online data curation adapts during learning, addressing the limitations of fixed strategies. Hard negative mining optimizes the selection of challenging examples, while model approximation techniques allow smaller models to act as proxies for larger ones, enhancing data selection efficiency during training.
The method selects the most relevant data sub-batches from a larger super-batch using model-based scoring functions, considering losses from both the learner and pretrained reference models. Prioritizing high-loss batches for the learner can discard trivial data but may also up-sample noise. Alternatively, selecting low-loss data for the reference model can identify high-quality examples but may be overly dependent on the reference model. Combining these approaches, learnability scoring prioritizes unlearned and learnable data, accelerating large-scale learning. Efficient scoring with online model approximation and multi-resolution training further optimizes the process.
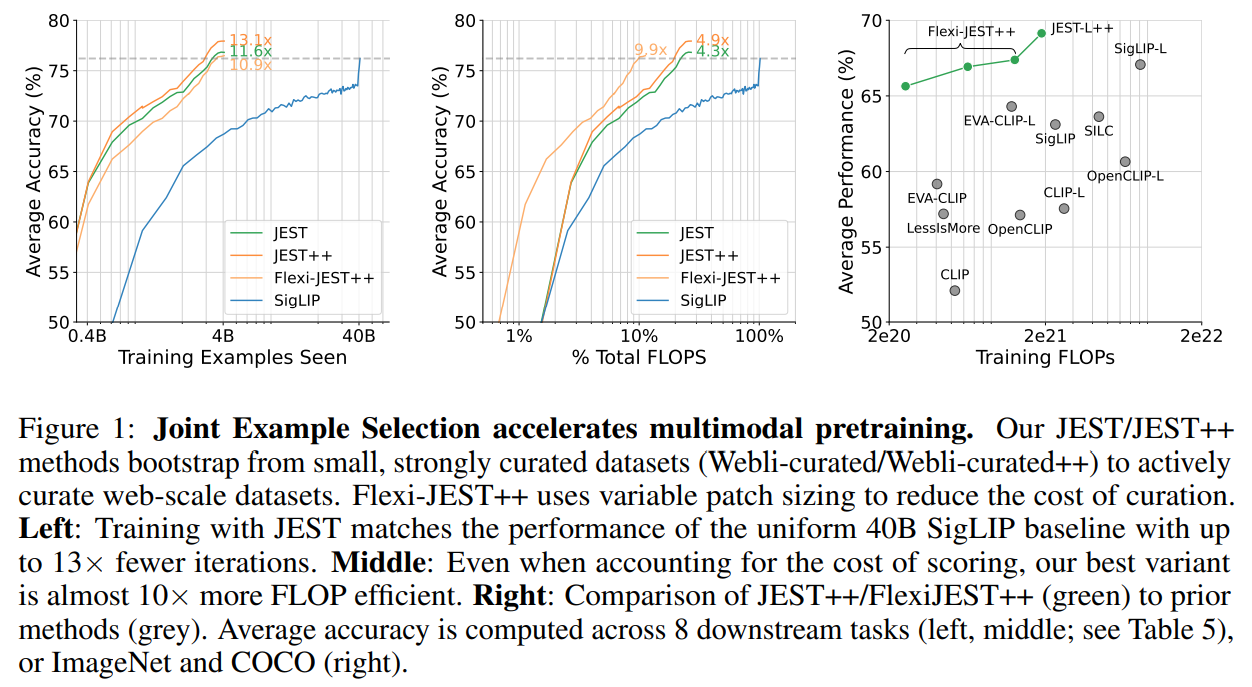
The efficacy of JEST for forming learnable batches was evaluated, revealing that JEST rapidly increases batch learnability with few iterations. It outperforms independent selection, achieving performance comparable to brute-force methods. In multimodal learning, JEST significantly accelerates training and improves final performance, with benefits scaling with filtering ratios. Flexi-JEST, a compute-efficient variant using multi-resolution training, also reduces computational overhead while maintaining speedups. JEST’s performance improves with stronger data curation, and it surpasses prior models on multiple benchmarks, demonstrating effectiveness in both training and compute efficiency.
In conclusion, The JEST method, designed for jointly selecting the most learnable data batches, significantly accelerates large-scale multimodal learning, achieving superior performance with up to 10× fewer FLOPs and 13× fewer examples. It highlights the potential for “data quality bootstrapping,” where small curated datasets guide learning on larger, uncurated ones. Unlike static dataset filtering, which can limit performance, online construction of useful batches enhances pretraining efficiency. This suggests that foundation distributions can effectively replace generic foundation datasets, whether through pre-scored datasets or dynamically adjusted with learnability JEST. However, the method relies on small, curated reference datasets, indicating a need for future research to infer reference datasets from downstream tasks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post Google DeepMind Introduces JEST: A New AI Training Method 13x Faster and 10X More Power Efficient appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]