


Introduction to Overfitting and Dropout:
Overfitting is a common challenge when training large neural networks on limited data. It occurs when a model performs exceptionally well on training data but fails to generalize to unseen test data. This problem arises because the network’s feature detectors become too specialized for the training data, developing complex dependencies that do not translate to the broader dataset.
Geoffrey Hinton and his team at the University of Toronto proposed an innovative solution to mitigate overfitting: Dropout. This technique involves randomly “dropping out” or deactivating half of the network’s neurons during training. By doing so, neurons are forced to learn more generalized features beneficial in various contexts rather than relying on the presence of specific other neurons.
How Dropout Works:
In a standard feedforward neural network, hidden layers between input and output layers adapt to detect features that aid in making predictions. When the network has many hidden units, and the relationship between input and output is intricate, multiple sets of weights can effectively model the training data. However, these models usually need to improve on new data because they overfit the training data through complex co-adaptations of feature detectors.
Dropout counters this by omitting each hidden unit with a 50% probability during each training iteration. This means each neuron cannot depend on other neurons’ presence, encouraging them to develop robust and independent feature detectors. This approach is a form of model averaging, where the network effectively trains on a vast ensemble of different network configurations. Unlike traditional model averaging, which is computationally intensive as it requires training and evaluating multiple separate networks, dropout efficiently manages this within a single training session.
Implementation Details
Dropout modifies the standard training process by:
1. Randomly Deactivating Neurons: Half of the neurons in each hidden layer are randomly deactivated during each training case. This prevents neurons from becoming reliant on others and encourages the development of more general features.
2. Weight Constraints: Instead of penalizing the network’s total weight, dropout constrains each neuron’s incoming weights. If a weight exceeds a predefined limit, it is scaled down. This constraint, combined with a gradually decreasing initial learning rate, allows for a thorough exploration of the weight space.
3. Mean Network at Test Time: When evaluating the network, all neurons are active, but their outgoing weights are halved to account for the increased number of active units. This “mean network” approach approximates the behavior of averaging predictions from the ensemble of dropout networks.
Performance on Benchmark Tasks
Hinton and his colleagues tested dropout on several benchmark tasks to assess its effectiveness:
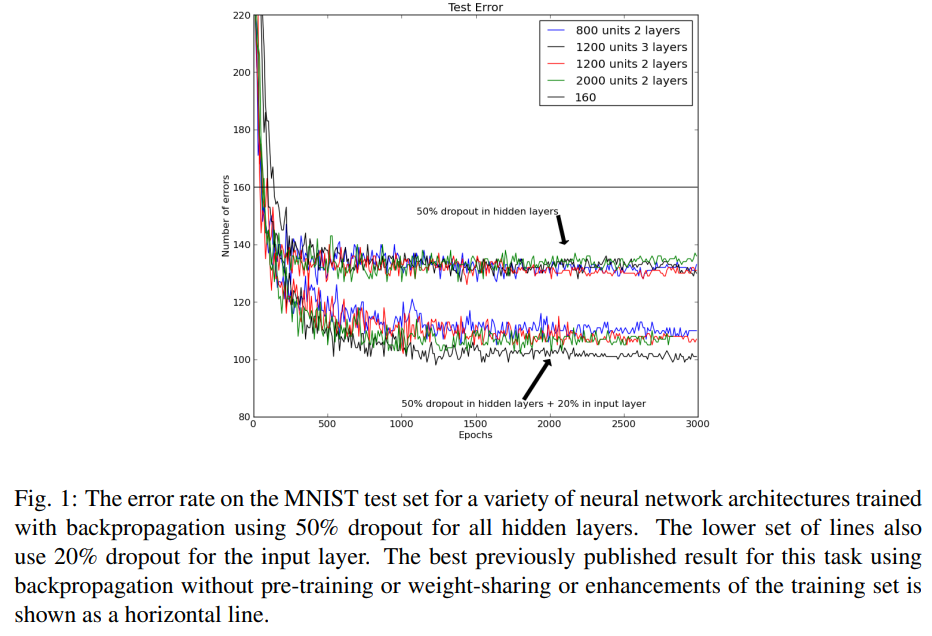
1. MNIST Digit Classification: On the MNIST dataset of handwritten digits, dropout significantly reduced test errors. The best result without enhancements or pre-training was 160 errors. Applying 50% dropout to the hidden layers and 20% dropout to the input layer reduced errors to about 110.
2. Speech Recognition with TIMIT: For the TIMIT dataset used in speech recognition, dropout improved the classification accuracy of frames in a time sequence. Without dropout, the recognition rate was 22.7%. With dropout, it improved to 19.7%, setting a new benchmark for methods not incorporating speaker identity information.
3. Object Recognition with CIFAR-10: On the CIFAR-10 dataset, which involves recognizing objects in low-resolution images, dropout applied to a neural network with three convolutional and pooling layers reduced the error rate from the best published 18.5% to 15.6%.
4. Large-Scale Object Recognition with ImageNet: On the challenging ImageNet dataset, which includes thousands of object classes, dropout reduced the error rate from 48.6% to a record 42.4%, demonstrating its robustness on large, complex tasks.
5. Text Classification with Reuters: For document classification in the Reuters dataset, dropout reduced the error rate from 31.05% to 29.62%, highlighting its applicability across different data types.
Dropout’s Broader Implications:
Dropout’s success is wider than specific tasks or datasets. It provides a general framework for improving neural networks’ ability to generalize from training data to unseen data. Its benefits extend beyond simple architectures to more complex models and can be integrated with advanced techniques like generative pre-training or convolutional networks.
Moreover, dropout offers a computationally efficient alternative to Bayesian model averaging and “bagging” methods, which require training multiple models and aggregating their predictions. By sharing weights across an exponentially large number of dropout networks, dropout achieves similar regularization and robustness without the computational overhead.
Analogies and Theoretical Insights:
Interestingly, dropout’s concept mirrors biological processes. In evolution, genetic diversity and the mixing of genes prevent the emergence of overly specialized traits that could become maladaptive. Similarly, dropout prevents neural networks from developing co-adapted sets of feature detectors, encouraging them to learn more robust and adaptable representations.
Conclusion:
Dropout is a notable improvement in neural network training, effectively mitigating overfitting and enhancing generalization. By hindering the co-adaptation of feature detectors, dropout enables the network to learn more versatile and broadly applicable features. As neural networks continue to grow, incorporating techniques like dropout will be essential for advancing the capabilities of these models and achieving better performance across diverse applications.
Sources:
The post Dropout: A Revolutionary Approach to Reducing Overfitting in Neural Networks appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]