


Artificial intelligence (AI) has seen significant advancements through game-playing agents like AlphaGo, which achieved superhuman performance via self-play techniques. Self-play allows models to improve by training on data generated from games played against themselves, proving effective in competitive environments like Go and chess. This technique, which pits identical copies of a model against each other, has pushed AI capabilities beyond human performance in these zero-sum games.
A persistent challenge in AI is enhancing performance in cooperative or partially cooperative language tasks. Unlike competitive games, where the objective is clear-cut, language tasks often require collaboration and maintaining human interpretability. The issue is whether self-play, successful in competitive settings, can be adapted to improve language models in tasks where cooperation with humans is essential. This involves ensuring that AI can communicate effectively and understand nuances in human language without deviating from natural, human-like communication strategies.
Existing research includes models like AlphaGo and AlphaZero, which use self-play for competitive games. Collaborative dialogue tasks like Cards, CerealBar, OneCommon, and DialOp evaluate models in cooperative settings using self-play as a proxy for human evaluation. Negotiation games like DoND and Craigslist Bargaining test models’ bartering abilities. However, these frameworks often struggle with maintaining human language interpretability and fail to generalize strategies effectively in mixed cooperative and competitive environments, limiting their real-world applicability.
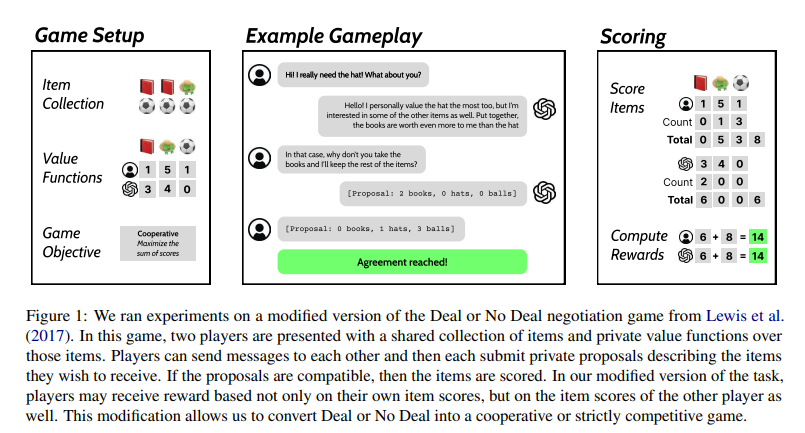
Researchers from the University of California, Berkeley, introduced a novel approach to test self-play in cooperative and competitive settings using a modified version of the negotiation game Deal or No Deal (DoND). This game, originally semi-competitive, was adapted to support various objectives, making it suitable for evaluating language model improvements across different collaboration levels. By modifying the reward structure, the game could simulate fully cooperative, semi-competitive, and strictly competitive environments, providing a versatile testbed for AI training.
In the modified DoND game, two players negotiate item division with private value functions. The game adjusts to cooperative, semi-competitive, or competitive settings. Researchers used filtered behavior cloning for self-play training. Two identical language models played 500 games per round over ten rounds, with high-scoring dialogues used for finetuning. Initial models, including GPT-3.5 and GPT-4, were evaluated without few-shot examples to avoid bias. The OpenAI Gym-like environment managed game rules, message handling, and rewards. Human experiments were conducted on Amazon Mechanical Turk with pre-screened workers to validate model performance.
The self-play training led to significant performance improvements. In cooperative and semi-competitive settings, models showed substantial gains, with scores improving by up to 2.5 times in cooperative and six times in semi-competitive scenarios compared to initial benchmarks. Specifically, models trained in the cooperative setting improved from an average score of 0.7 to 12.1, while in the semi-competitive setting, scores increased from 0.4 to 5.8. This demonstrates the potential of self-play to enhance language models’ ability to cooperate and compete effectively with humans, suggesting that these techniques can be adapted for more complex, real-world tasks.
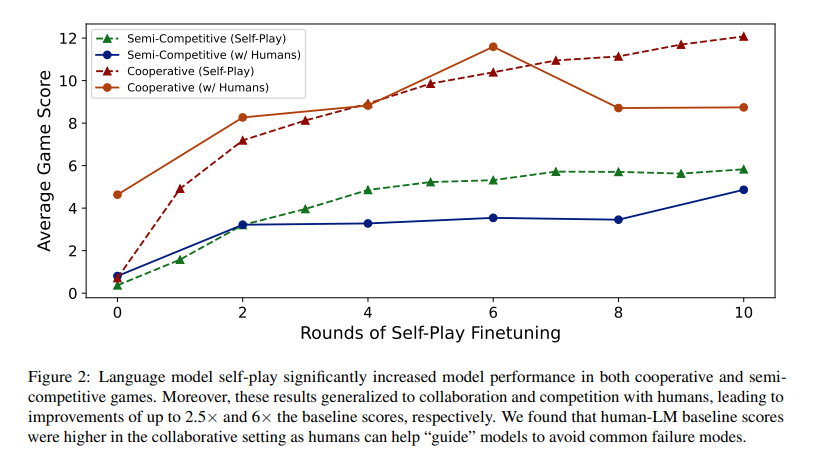
Despite the promising results in cooperative and semi-competitive environments, the strictly competitive setting posed challenges. Improvements were minimal, indicating that models tended to overfit during self-play. In this setting, models often struggled to generalize their strategies, failing to reach valid agreements with other agents, such as GPT-4. Preliminary human experiments further showed that these models rarely achieved agreements, highlighting the difficulty of applying self-play in zero-sum scenarios where robust, generalizable strategies are crucial.
To conclude, this research, conducted by the University of California, Berkeley team, underscores the potential of self-play in training language models for collaborative tasks. The findings challenge the prevailing assumption that self-play is ineffective in cooperative domains or that models need extensive human data to maintain language interpretability. Instead, the significant improvements observed after just ten rounds of self-play suggest that language models with good generalization abilities can benefit from these techniques. This could lead to broader applications of self-play beyond competitive games, potentially enhancing AI’s performance in various collaborative and real-world tasks.
Check out the Paper and Code. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 45k+ ML SubReddit
The post This AI Paper by UC Berkeley Explores the Potential of Self-play Training for Language Models in Cooperative Tasks appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]