


Reinforcement learning from human feedback (RLHF) encourages generations to have high rewards, using a reward model trained on human preferences to align large language models (LLMs). However, RLHF has several unresolved issues. First, the fine-tuning process is often limited to small datasets, causing the model to become too specialized and miss the wide range of knowledge it learned during pre-training. This can lower the LLM’s reasoning abilities and performance on NLP benchmarks. Second, trying to maximize an imperfect reward model (RM) can lead to problems, as the LLM might find ways to exploit flaws in the RM. Lastly, RLHF can reduce the variety of outputs, causing the model to collapse to produce similar responses.
This paper discusses two related topics. The first topic is how to merge models. Recently, the idea of merging deep models in the weight space, rather than in the prediction space as traditionally done in ensembling, has gained great attention. This method is called weight averaging (WA), and the most common form of WA is LERP. This form was initially used to average checkpoints from a single run, uniformly or with an exponential moving average (EMA). The second topic is the benefits of model merging, where WA improves generalization by reducing variance, memorization, and flattening the loss landscape. Moreover, merging weights combines their strengths, which is useful in multi-task setups.
A team from Google DeepMind has proposed Weight Averaged Rewarded Policies (WARP), a method to align LLMs and optimize the Kullback-Leibler(KL)-reward Pareto front of solutions. WARP uses three types of WA at three stages of the alignment process for distinct reasons. First, it uses the exponential moving average of the policy in the KL regularization as a flexible reference point. Second, it merges fine-tuned policies into an improved policy through spherical interpolation. Third, it linearly interpolates between the merged model and the initialization, to get back features from pre-training. This process is repeated, where each final model serves as a starting point for the next iteration, and enhances the KL-reward Pareto front, obtaining better rewards at fixed KL.
In the experiment carried out by the team, Gemma “7B” LLM is considered and fine-tuned with RLHF into a better conversational agent. Moreover, the REINFORCE policy gradient is also utilized to optimize the KL-regularized reward. After that, on-policy samples are generated using the dataset which includes conversation prompts, with a temperature of 0.9, batch size of 128, Adam optimizer with learning rate 10−6, warmup of 100 steps, and SLERP is applied to the 28 layers separately. It’s important to note that this experiment relies on the high-capacity reward model, the largest available, which prevents the use of an oracle control RM.
Side-by-side comparisons were made for the trained policies against Mistral and Mixtral LLMs. Each policy generated a candidate answer from a set of prompts as described in the Gemma tech report. Similar to Gemini 1.5, side-by-side preference rates were calculated with “much better”, “better” and “slightly better” receiving scores of ±1.5, ±1, and ±0.5 respectively, and ties receiving a score of 0. A positive score means better policies. The results validate that WARP is efficient, as the proposed policies were preferred over the Mistral variants and outperformed the previous Gemma “7B” releases.
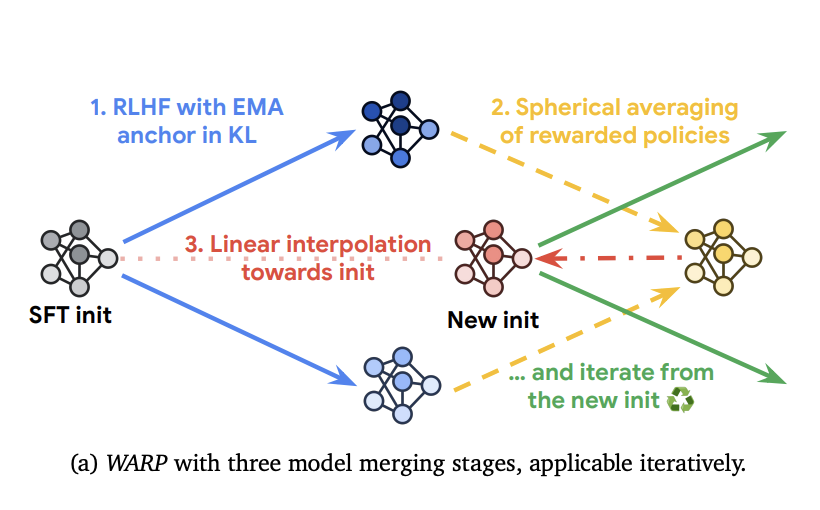
In conclusion, a team from Google DeepMind has introduced (WARP), a novel RLHF method to align LLMs and optimize the KL-reward Pareto front of solutions. It uses three distinct stages of model merging, (a) exponential moving average as a dynamic anchor during RL, (b) spherical interpolation to combine multiple policies rewarded independently, and (c) interpolation towards the shared initialization. This iterative application of WARP improves the KL-reward Pareto front, aligning the LLMs while protecting the knowledge from pre-training, and compares favorably against state-of-the-art baselines. In the future, WARP could help create safe and powerful AI systems by improving alignment and encouraging further study of model merging techniques.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 45k+ ML SubReddit
 Create, edit, and augment tabular data with the first compound AI system, Gretel Navigator, now generally available! [Advertisement]
Create, edit, and augment tabular data with the first compound AI system, Gretel Navigator, now generally available! [Advertisement]
The post Google DeepMind Introduces WARP: A Novel Reinforcement Learning from Human Feedback RLHF Method to Align LLMs and Optimize the KL-Reward Pareto Front of Solutions appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]