


Large language models (LLMs) have made significant strides in handling multiple modalities and tasks, but they still need to improve their ability to process diverse inputs and perform a wide range of tasks effectively. The primary challenge lies in developing a single neural network capable of handling a broad spectrum of tasks and modalities while maintaining high performance across all domains. Current models, such as 4M and UnifiedIO, show promise but are constrained by the limited number of modalities and tasks they are trained on. This limitation hinders their practical application in scenarios requiring truly versatile and adaptable AI systems.
Recent attempts to solve multitask learning challenges in vision have evolved from combining dense vision tasks to integrating numerous tasks into unified multimodal models. Methods like Gato, OFA, Pix2Seq, UnifiedIO, and 4M transform various modalities into discrete tokens and train Transformers using sequence or masked modeling objectives. Some approaches enable a wide range of tasks through co-training on disjoint datasets, while others, like 4M, use pseudo labeling for any-to-any modality prediction on aligned datasets. Masked modeling has proven effective in learning cross-modal representations, crucial for multimodal learning, and enables generative applications when combined with tokenization.
Researchers from Apple and the Swiss Federal Institute of Technology Lausanne (EPFL) build their method upon the multimodal masking pre-training scheme, significantly expanding its capabilities by training on a diverse set of modalities. The approach incorporates over 20 modalities, including SAM segments, 3D human poses, Canny edges, color palettes, and various metadata and embeddings. By using modality-specific discrete tokenizers, the method encodes diverse inputs into a unified format, enabling the training of a single model on multiple modalities without performance degradation. This unified approach expands existing capabilities across several key axes, including increased modality support, improved diversity in data types, effective tokenization techniques, and scaled model size. The resulting model demonstrates new possibilities for multimodal interaction, such as cross-modal retrieval and highly steerable generation across all training modalities.
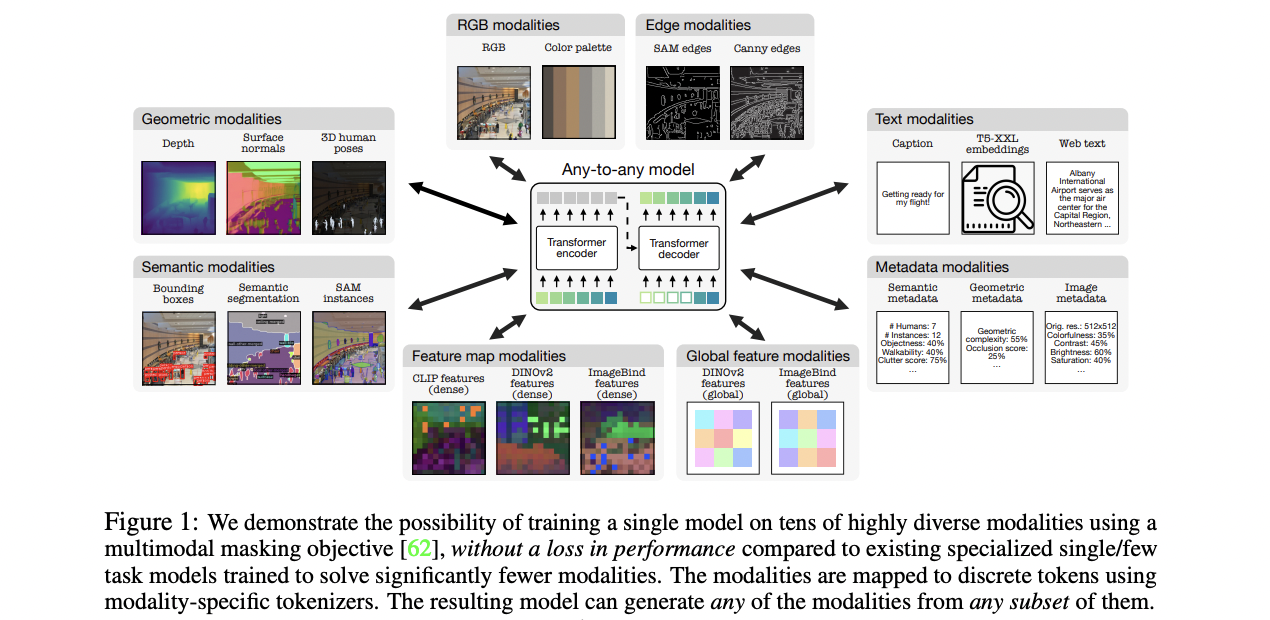
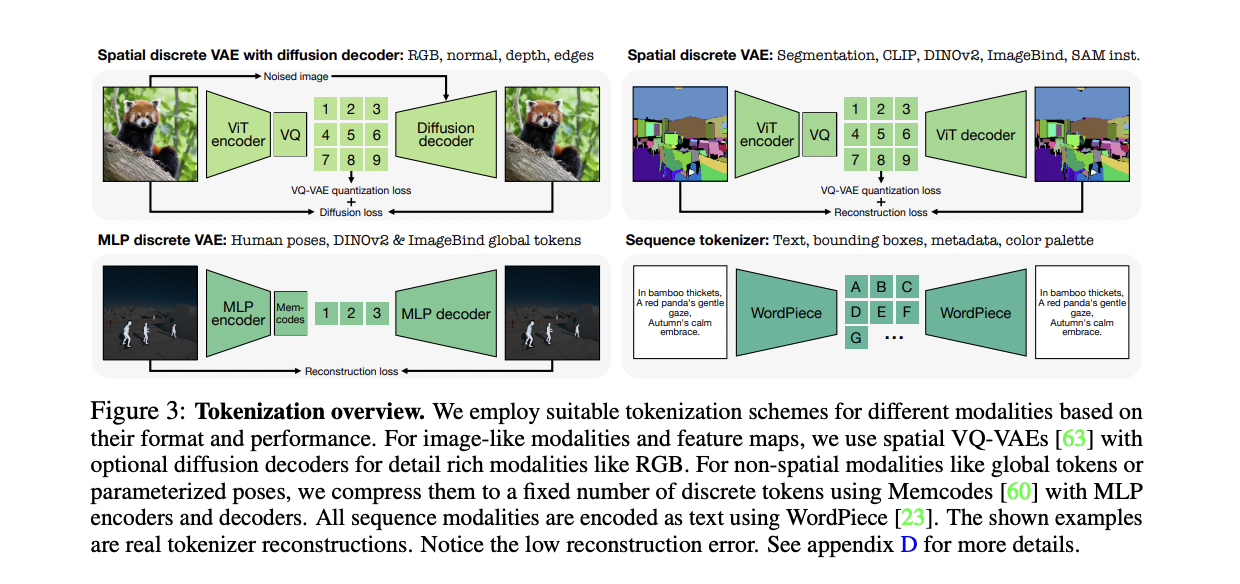
This method adopts the 4M pre-training scheme, expanding it to handle a diverse set of modalities. It transforms all modalities into sequences of discrete tokens using modality-specific tokenizers. The training objective involves predicting one subset of tokens from another, using random selections from all modalities as inputs and targets. It utilizes pseudo-labeling to create a large pre-training dataset with multiple aligned modalities. The method incorporates a wide range of modalities, including RGB, geometric, semantic, edges, feature maps, metadata, and text. Tokenization plays a crucial role in unifying the representation space across these diverse modalities. This unification enables training with a single pre-training objective, improves training stability, allows full parameter sharing, and eliminates the need for task-specific components. Three main types of tokenizers are employed: ViT-based tokenizers for image-like modalities, MLP tokenizers for human poses and global embeddings, and a WordPiece tokenizer for text and other structured data. This comprehensive tokenization approach allows the model to handle a wide array of modalities efficiently, reducing computational complexity and enabling generative tasks across multiple domains.
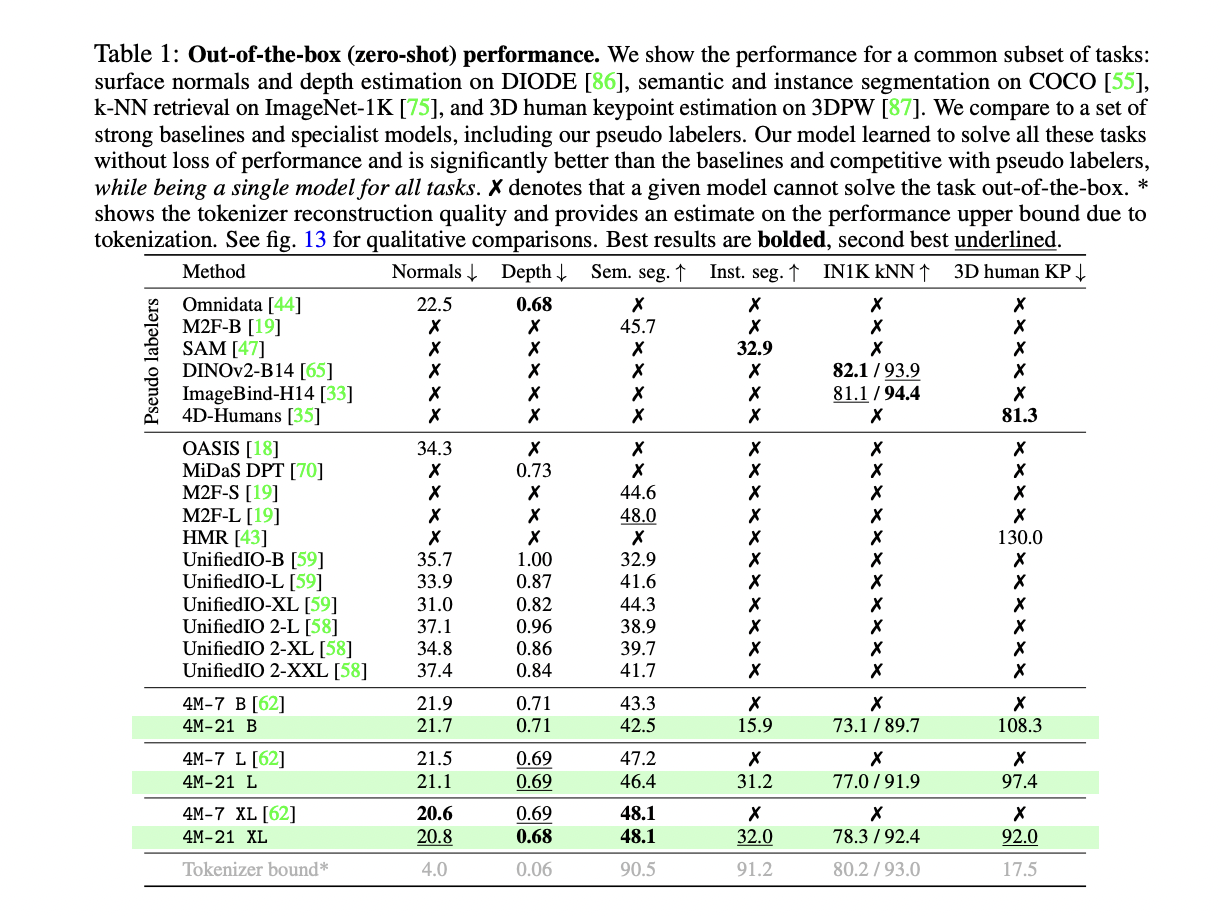
The 4M-21 model demonstrates a wide range of capabilities, including steerable multimodal generation, multimodal retrieval, and strong out-of-the-box performance across various vision tasks. It can predict any training modality by iteratively decoding tokens, enabling fine-grained and multimodal generation with improved text understanding. The model performs multimodal retrievals by predicting global embeddings from any input modality, allowing for versatile retrieval capabilities. In out-of-the-box evaluations, 4M-21 achieves competitive performance on tasks such as surface normal estimation, depth estimation, semantic segmentation, instance segmentation, 3D human pose estimation, and image retrieval. It often matches or outperforms specialist models and pseudo-labelers while being a single model for all tasks. The 4M-21 XL variant, in particular, demonstrates strong performance across multiple modalities without sacrificing capability in any single domain.

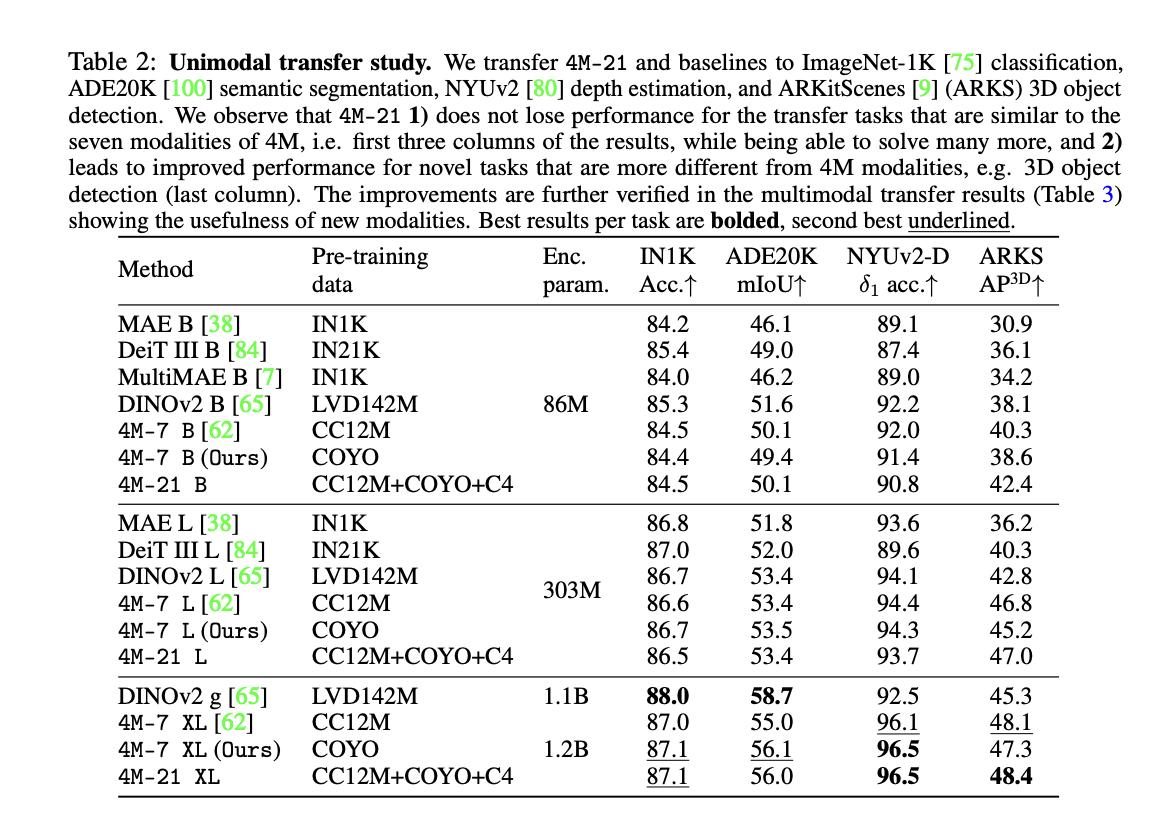
Researchers examine the scaling characteristics of pre-training any-to-any models on a large set of modalities, comparing three model sizes: B, L, and XL. Evaluating both unimodal (RGB) and multimodal (RGB + Depth) transfer learning scenarios. In unimodal transfers, 4M-21 maintains performance on tasks similar to the original seven modalities while showing improved results on complex tasks like 3D object detection. The model demonstrates better performance with increased size, indicating promising scaling trends. For multimodal transfers, 4M-21 effectively utilizes optional depth inputs, significantly outperforming baselines. The study reveals that training on a broader set of modalities does not compromise performance on familiar tasks and can enhance capabilities on new ones, especially as model size increases.
This research demonstrates the successful training of an any-to-any model on a diverse set of 21 modalities and tasks. This achievement is made possible by employing modality-specific tokenizers to map all modalities to discrete sets of tokens, coupled with a multimodal masked training objective. The model scales to three billion parameters across multiple datasets without compromising performance compared to more specialized models. The resulting unified model exhibits strong out-of-the-box capabilities and opens new avenues for multimodal interaction, generation, and retrieval. However, the study acknowledges certain limitations and areas for future work. These include the need to further explore transfer and emergent capabilities, which remain largely untapped compared to language models.
Check out the Paper, Project, and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 44k+ ML SubReddit
The post Apple Releases 4M-21: A Very Effective Multimodal AI Model that Solves Tens of Tasks and Modalities appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #ComputerVision #EditorsPick #LanguageModel #LargeLanguageModel #MultimodalAI #Staff #TechNews #Technology [Source: AI Techpark]