


Temporal reasoning involves understanding and interpreting the relationships between events over time, a crucial capability for intelligent systems. This field of research is essential for developing AI that can handle tasks ranging from natural language processing to decision-making in dynamic environments. AI can perform complex operations like scheduling, forecasting, and historical data analysis by accurately interpreting time-related data. This makes temporal reasoning a foundational aspect of developing advanced AI systems.
Despite the importance of temporal reasoning, existing benchmarks often need to be revised. They rely heavily on real-world data that LLMs may have seen during training or use anonymization techniques that can lead to inaccuracies. This creates a need for more robust evaluation methods that accurately measure LLMs’ abilities in temporal reasoning. The primary challenge lies in creating benchmarks that test memory recall and genuinely evaluate reasoning skills. This is critical for applications requiring precise and context-aware temporal understanding.
Current research includes the development of synthetic datasets for probing LLM capabilities, such as logical and mathematical reasoning. Frameworks like TempTabQA, TGQA, and knowledge graph-based benchmarks are widely used. However, these methods are limited by the inherent biases and pre-existing knowledge within the models. This often results in evaluations that do not truly reflect the models’ reasoning capabilities but rather their ability to recall learned information. The focus on well-known entities and facts needs to adequately challenge the models’ understanding of temporal logic and arithmetic, leading to an incomplete assessment of their true capabilities.
To address these challenges, researchers from Google Research, Google DeepMind, and Google have introduced the Test of Time (ToT) benchmark. This innovative benchmark uses synthetic datasets specifically designed to evaluate temporal reasoning without relying on the models’ prior knowledge. The benchmark is open-sourced to encourage further research and development in this area. The introduction of ToT represents a significant advancement, providing a controlled environment to systematically test and improve LLMs’ temporal reasoning skills.
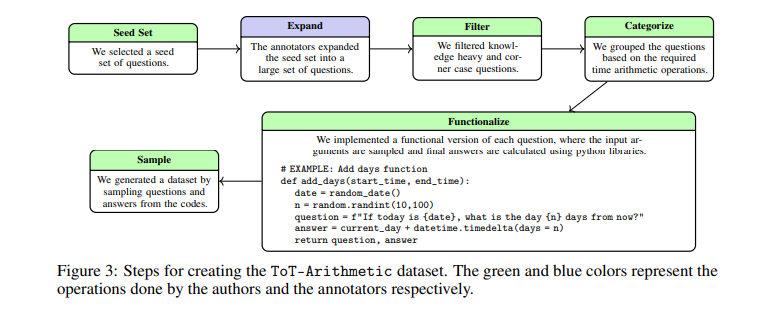
The ToT benchmark consists of two main tasks. ToT-Semantic focuses on temporal semantics and logic, allowing for flexible exploration of diverse graph structures and reasoning complexities. This task isolates core reasoning abilities from pre-existing knowledge. ToT-Arithmetic assesses the ability to perform calculations involving time points and durations, using crowd-sourced tasks to ensure practical relevance. These tasks are meticulously designed to cover various temporal reasoning scenarios, providing a thorough evaluation framework.
To create the ToT-Semantic task, researchers generated random graph structures using algorithms such as Erdős-Rényi and Barabási-–Albert models. These graphs were then used to create diverse temporal questions, allowing for an in-depth assessment of LLMs’ ability to understand and reason about time. For ToT-Arithmetic, tasks were designed to test practical arithmetic involving time, such as calculating durations and handling time zone conversions. This dual approach ensures a comprehensive evaluation of both logical and arithmetic aspects of temporal reasoning.
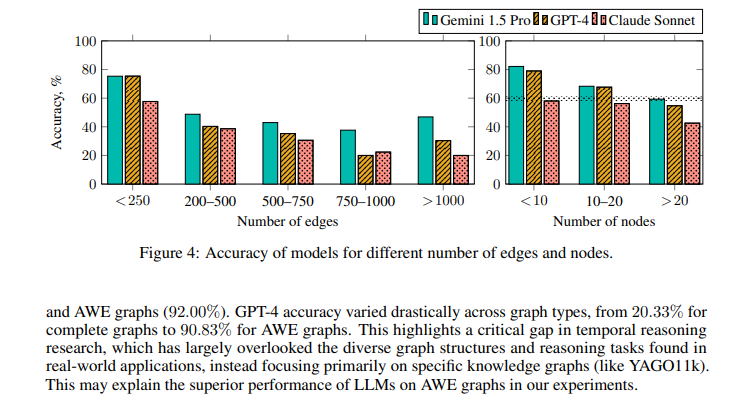
Experimental results using the ToT benchmark reveal significant insights into the strengths and weaknesses of current LLMs. For instance, GPT-4’s performance varied widely across different graph structures, with accuracy ranging from 40.25% on complete graphs to 92.00% on AWE graphs. These findings highlight the impact of temporal structure on reasoning performance. Furthermore, the order of facts presented to the models significantly influenced their performance, with the highest accuracy observed when the target entity sorted facts and start time.
The study also explored the types of temporal questions and their difficulty levels. Single-fact questions were easier for models to handle, while multi-fact questions, requiring integration of multiple pieces of information, posed more challenges. For example, GPT-4 achieved 90.29% accuracy on EventAtWhatTime questions but struggled with Timeline questions, indicating a gap in handling complex temporal sequences. The detailed analysis of question types and model performance provides a clear picture of current capabilities and areas needing improvement.
In conclusion, the ToT benchmark represents a significant advancement in evaluating LLMs’ temporal reasoning capabilities. Providing a more comprehensive and controlled assessment framework helps identify areas for improvement and guides the development of more capable AI systems. This benchmark sets the stage for future research to enhance the temporal reasoning abilities of LLMs, ultimately contributing to the broader goal of achieving artificial general intelligence.
Check out the Paper and HF Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 44k+ ML SubReddit
The post Separating Fact from Logic: Test of Time ToT Benchmark Isolates Reasoning Skills in LLMs for Improved Temporal Understanding appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]