


The release of the Tulu 2.5 suite by the Allen Institute for AI marks a significant advancement in model training using Direct Preference Optimization (DPO) and Proximal Policy Optimization (PPO). The Tulu 2.5 suite comprises diverse models trained on various datasets to enhance their reward and value models. This suite is poised to substantially improve language model performance across several domains, including text generation, instruction following, and reasoning.
Overview of Tulu 2.5 Suite
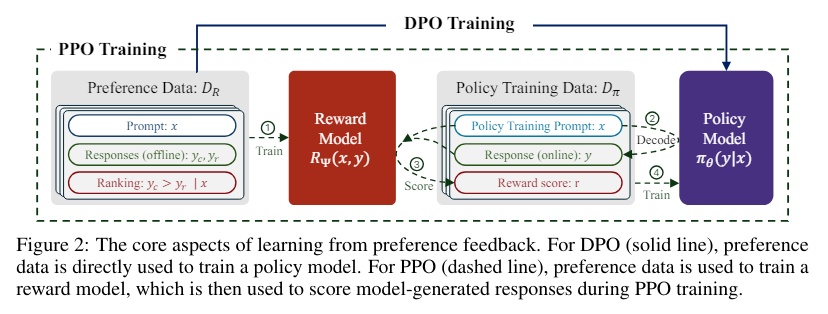
The Tulu 2.5 suite includes a collection of models meticulously trained using DPO and PPO methods. These models leverage preference datasets, which are critical for refining the performance of language models by incorporating human-like preferences into their learning process. The suite aims to enhance various capabilities of language models, such as truthfulness, safety, coding, and reasoning, making them more robust and reliable for diverse applications. The Tulu 2.5 suite includes several variants of the models, each tailored to specific tasks and optimized using different datasets and methodologies. Here are some notable variants:
- Tulu 2.5 PPO 13B UF Mean 70B UF RM: This variant represents the best model in the suite. It is a 13 billion Tulu 2 model trained using PPO with a 70 billion parameter reward model trained on UltraFeedback data. This combination has been shown to deliver superior performance in text-generation tasks.
- Tulu 2.5 PPO 13B Chatbot Arena 2023: This variant enhances chatbot capabilities. It is specifically trained using data from the 2023 Chatbot Arena, which includes diverse prompts and responses to improve conversational abilities and user interaction quality.
- Tulu 2.5 DPO 13B StackExchange 60K: Trained using DPO, this 13 billion-parameter model utilizes 60,000 samples from StackExchange. This training approach enhances the model’s ability to generate accurate and contextually appropriate responses based on StackExchange’s extensive knowledge base.
- Tulu 2.5 DPO 13B Nectar 60K: Another DPO-trained variant, this model uses 60,000 samples from the Nectar dataset. The Nectar dataset is known for its high-quality synthetic data, which helps improve the model’s performance in tasks requiring complex reasoning and factual accuracy.
- Tulu 2.5 PPO 13B HH-RLHF 60K: This variant employs PPO training with 60,000 samples from the HH-RLHF (Human-Human Reinforcement Learning from Human Feedback) dataset. This approach focuses on refining the model’s reward mechanisms based on detailed human feedback, improving responsiveness and user alignment.
- Tulu 2.5 DPO 13B PRM Phase 2: This variant focuses on the second phase of preference data, specifically targeting performance improvements in mathematical reasoning and problem-solving capabilities. It uses DPO training to optimize the model’s ability to understand and generate accurate mathematical content.
- Tulu 2.5 DPO 13B HelpSteer: This variant is trained on the HelpSteer dataset, which includes preference data to improve the helpfulness and clarity of the model’s responses. The DPO training methodology ensures the model can effectively learn from user feedback to provide more useful and accurate information.
Key Components and Training Methodologies
- Preference Data: The foundation of the Tulu 2.5 suite is built on high-quality preference datasets. These datasets consist of prompts, responses, and rankings, which help train the models to prioritize responses that align closely with human preferences. The suite includes datasets from various sources, including human annotations, web scraping, and synthetic data, ensuring a comprehensive training regime.
- DPO vs. PPO: The suite employs both DPO and PPO training methodologies. DPO, an offline reinforcement learning approach, optimizes the policy directly on preference data without needing online response generation. On the other hand, PPO involves an initial stage of training a reward model followed by policy optimization using online response generation. This dual approach allows the suite to benefit from the strengths of both methodologies, leading to superior performance across different benchmarks.
- Reward and Value Models: The Tulu 2.5 suite includes various reward models trained on extensive datasets. These reward models are crucial for scoring the generated responses, guiding the optimization process, and enhancing the model’s performance. The value models included in the suite help in token classification and other related tasks, contributing to the overall effectiveness of the suite.
Performance and Evaluation
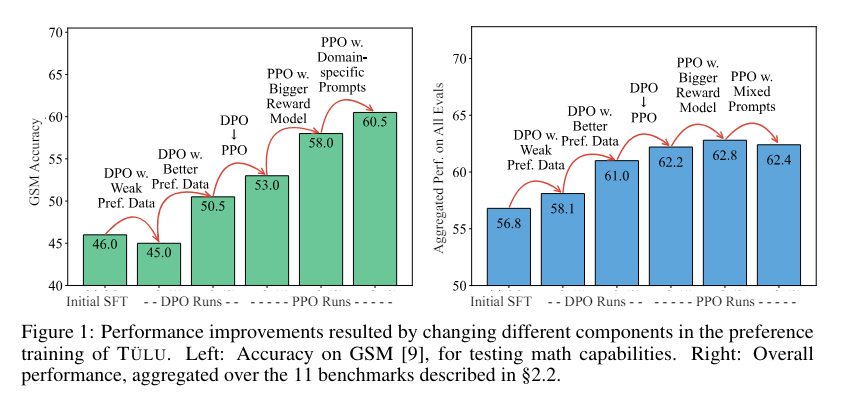
The Tulu 2.5 models have undergone rigorous evaluation across various benchmarks. The evaluation covers critical areas such as factuality, reasoning, coding, instruction following, and safety. The results demonstrate that models trained with PPO generally outperform those trained with DPO, particularly in reasoning, coding, and safety. For instance, PPO-trained models exhibit superior performance in chain-of-thought reasoning, essential for tackling complex mathematical problems and logical reasoning tasks.
Notable Improvements
- Instruction Following and Truthfulness: The Tulu 2.5 suite significantly improves instruction following and truthfulness, with models trained on high-quality preference data outperforming baseline models by substantial margins. This improvement is particularly evident in chat-related abilities, where the models are better at adhering to user instructions and providing truthful responses.
- Scalability: The suite includes varying sizes, with reward models scaled up to 70 billion parameters. This scalability allows the suite to cater to different computational capacities while maintaining high performance. When used during PPO training, the larger reward models result in notable gains in specific domains like mathematics.
- Synthetic Data: Synthetic preference datasets, such as UltraFeedback, have proven highly effective in enhancing model performance. These datasets, annotated with per-aspect preferences, offer a detailed and nuanced approach to preference-based learning, resulting in models that better understand and prioritize user preferences.
The release of the Tulu 2.5 suite underscores the importance of continuous exploration and refinement of learning algorithms, reward models, and preference data. Future work will likely optimize these components to achieve even greater performance gains. Expanding the suite to include more diverse and comprehensive datasets will be crucial in maintaining its relevance and effectiveness in an ever-evolving AI landscape.
In conclusion, the Tulu 2.5 suite by the Allen Institute for AI represents a significant leap forward in preference-based learning for language models. This suite sets a new benchmark for AI model performance and reliability by integrating advanced training methodologies and leveraging high-quality datasets.
Check out the Paper and Models. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 44k+ ML SubReddit
The post Allen Institute for AI Releases Tulu 2.5 Suite on Hugging Face: Advanced AI Models Trained with DPO and PPO, Featuring Reward and Value Models appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]