


Large Language Models (LLMs) face challenges in capturing complex long-term dependencies and achieving efficient parallelization for large-scale training. Attention-based models have dominated LLM architectures due to their ability to address these issues. However, they struggle with computational complexity and extrapolation to longer sequences. State Space Models (SSMs) have emerged as a promising alternative, offering linear computation complexity and the potential for better extrapolation. Despite these advantages, SSMs struggle with memory recall due to their Markovian nature and are less competitive in information retrieval-related tasks than attention-based models.
Researchers have attempted to combine State Space Models (SSMs) and attention mechanisms to utilize the strengths of both approaches. However, these hybrid models have not achieved unlimited-length extrapolation with linear-time complexity. Existing length generalization techniques developed for attention mechanisms face limitations such as quadratic computation complexity or restricted context extrapolation ability. Despite these efforts, no solution has successfully addressed all the challenges simultaneously.
Researchers from Microsoft and the University of Illinois at Urbana-Champaign present SAMBA, a simple neural architecture that harmonizes the strengths of both the SSM and the attention-based models achieving unlimited sequence length extrapolation with linear time complexity. SAMBA’s architecture interleaves Mamba, SwiGLU, and Sliding Window Attention (SWA) layers. Mamba layers capture time-dependent semantics and enable efficient decoding, while SWA models complex, non-Markovian dependencies. The researchers have scaled SAMBA to various sizes, with the largest 3.8B parameter model pre-trained on 3.2T tokens. This model demonstrates impressive performance on benchmarks like MMLU, HumanEval, and GSM8K, outperforming other open-source language models up to 8B parameters.
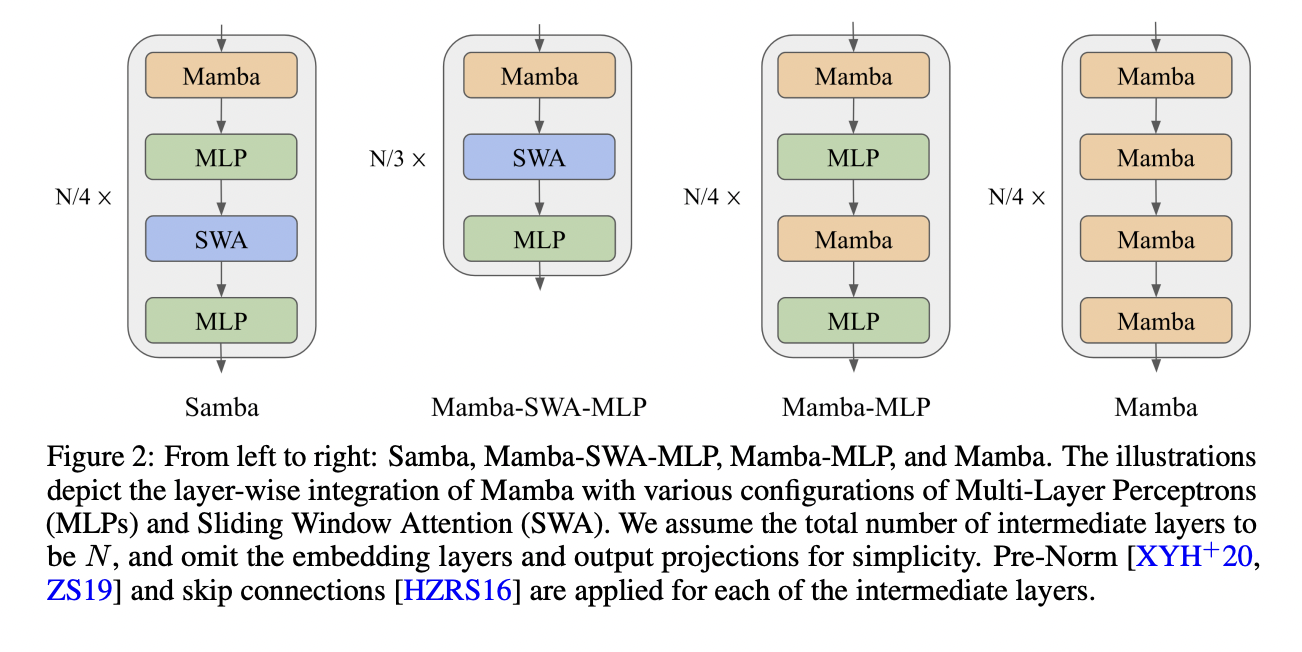
SAMBA’s architecture innovatively combines Mamba, SWA, and Multi-Layer Perceptron (MLP) layers. Mamba layers capture time-dependent semantics using selective state spaces, while SWA layers address non-Markovian dependencies through a sliding window approach. MLP layers, implemented as SwiGLU, handle nonlinear transformations and factual knowledge recall. The researchers explored various hybridization strategies, including Samba, Mamba-SWA-MLP, and Mamba-MLP, at the 1.7B parameter scale. This hybrid approach aims to harmonize the distinct functionalities of each layer type, creating an efficient architecture for language modeling with unlimited-length extrapolation ability.
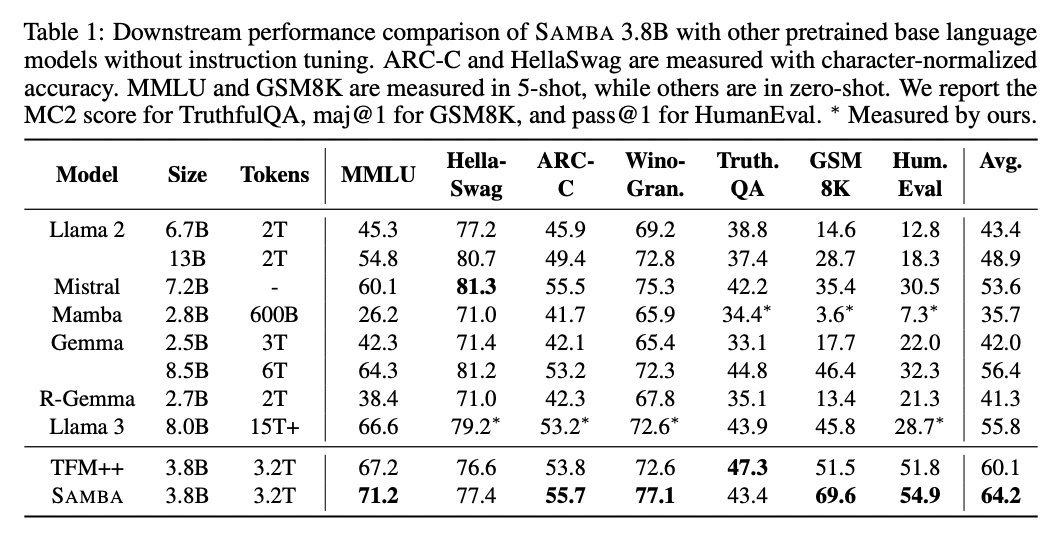
SAMBA’s performance was evaluated across various parameter sizes (421M, 1.3B, 1.7B, and 3.8B) and compared with other architectures. The 3.8B SAMBA model, trained on 3.2T tokens, outperformed strong baselines like Llama 2, Mistral, Mamba, Gemma, and Llama 3 across diverse benchmarks. It excelled in tasks such as commonsense reasoning, language understanding, truthfulness, math, and coding. Notably, SAMBA achieved an 18.1% higher accuracy on GSM8K compared to Transformer++. At the 1.7B scale, SAMBA demonstrated superior performance in various tasks, outperforming both pure attention-based and SSM-based models. The results highlight the effectiveness of SAMBA’s hybrid architecture in combining the strengths of Mamba, SWA, and MLP layers.
SAMBA represents a significant advancement in language modeling, combining the strengths of attention mechanisms and State Space Models. Its hybrid architecture demonstrates superior performance across various benchmarks, outperforming pure attention-based and SSM-based models. SAMBA’s ability to handle unlimited context length efficiently, coupled with its remarkable memory extrapolation capabilities, makes it particularly suited for real-world applications requiring extensive context understanding. The architecture’s optimal balance between attention and recurrent structures results in a powerful, efficient model that pushes the boundaries of language modeling, offering promising solutions for complex natural language processing tasks.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 44k+ ML SubReddit
Introducing Samba 3.8B, a simple Mamba+Sliding Window Attention architecture that outperforms Phi3-mini on major benchmarks (e.g., MMLU, GSM8K and HumanEval) by a large margin.
And it has an infinite context length with linear complexity.
Paper: https://t.co/6OnfGG71Aj… pic.twitter.com/f4IZdT1wGB
— Liliang Ren (@liliang_ren) June 12, 2024

The post Microsoft Researchers Introduce Samba 3.8B: A Simple Mamba+Sliding Window Attention Architecture that Outperforms Phi3-mini on Major Benchmarks appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #Technology [Source: AI Techpark]