


Artificial intelligence’s large language models (LLMs) have become essential tools due to their ability to process and generate human-like text, enabling them to perform various tasks. These models rely heavily on high-quality instruction datasets for fine-tuning, which enhances their ability to understand and follow complex instructions. The success of LLMs in various applications, from chatbots to data analysis, hinges on the diversity and quality of the instruction data they are trained with.
Access to high-quality, diverse instruction datasets necessary for aligning LLMs is one of many challenges for the field. Although some models like Llama-3 have open weights, the associated alignment data often remains proprietary, restricting broader research and development efforts. Constructing large-scale instruction datasets is labor-intensive and costly, making achieving the necessary scale and diversity difficult. This limitation hinders the advancement of LLM capabilities and their application in diverse, real-world scenarios.
Existing methods for generating instruction datasets fall into two categories: human-curated data and synthetic data produced by LLMs. Human-curated datasets, while precise, could be more scalable due to the high costs and time required for manual data generation and curation. On the other hand, synthetic data generation methods involve using LLMs to produce instructions based on initial seed questions and prompt engineering. However, these methods often need more diversity as the dataset size increases, as the generated instructions tend to be too similar to the seed questions.
Researchers from the University of Washington and Allen Institute for AI introduced a novel method called MAGPIE. MAGPIE leverages the auto-regressive nature of aligned LLMs to generate high-quality instruction data at scale. This method involves prompting the LLM with only predefined templates, allowing the model to create user queries and their corresponding responses autonomously. This approach eliminates the need for manual prompt engineering and seed questions, ensuring a diverse and extensive instruction dataset.
The MAGPIE method consists of two main steps:
- Instruction generation
- Response generation
In the instruction generation step, predefined templates are input into an aligned LLM, such as Llama-3-8B-Instruct. The model then generates diverse user queries based on these templates. In the response generation step, these queries prompt the LLM again to produce corresponding responses, resulting in complete instruction-response pairs. This automated process is efficient, requiring no human intervention and utilizing 206 and 614 GPU hours to generate the MAGPIE-Air and MAGPIE-Pro datasets.
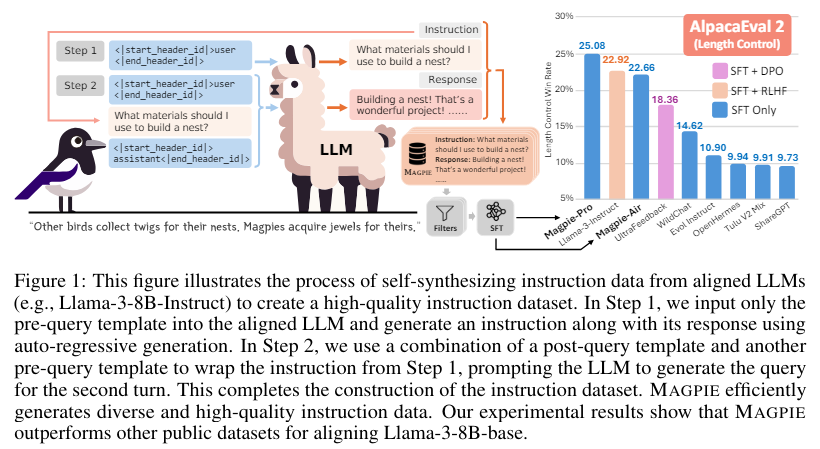
Researchers applied the MAGPIE method to create two instruction datasets, MAGPIE-Air and MAGPIE-Pro, generated using Llama-3-8B-Instruct and Llama-3-70B-Instruct models, respectively. These datasets include single-turn and multi-turn instructions, with MAGPIE-Air-MT and MAGPIE-Pro-MT containing sequences of multi-turn instructions and responses. The generated datasets were then filtered to select high-quality instances, resulting in MAGPIE-Air-300K-Filtered and MAGPIE-Pro-300K-Filtered datasets.
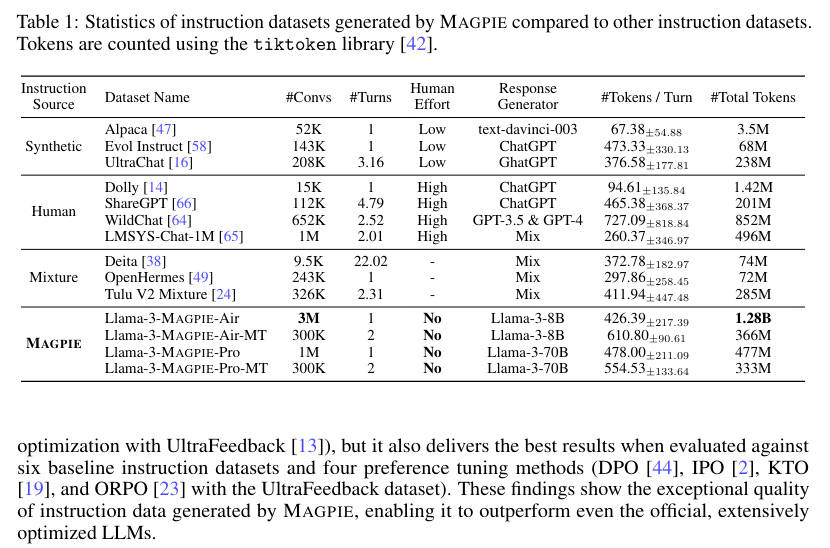
The performance of models fine-tuned with MAGPIE datasets was compared against those trained with other public instruction datasets, such as ShareGPT, WildChat, Evol Instruct, UltraChat, and OpenHermes. The results indicated that models fine-tuned with MAGPIE data performed comparably to the official Llama-3-8B-Instruct model, which was trained using over 10 million data points. For instance, the models fine-tuned with MAGPIE datasets achieved a win rate (WR) of 29.47% against GPT-4-Turbo (1106) on the AlpacaEval 2 benchmark and surpassed the official model on various alignment benchmarks, including Arena-Hard and WildBench.

In conclusion, the introduction of the MAGPIE method represents a significant advancement in the scalable generation of high-quality instruction datasets for LLM alignment. By automating the data generation process and eliminating the need for prompt engineering and seed questions, MAGPIE ensures a diverse and extensive dataset, enabling LLMs to perform better on various tasks. The efficiency and effectiveness of MAGPIE make it a valuable tool for researchers and developers looking to enhance the capabilities of LLMs.
Check out the Paper, Project, and Models. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 44k+ ML SubReddit
The post MAGPIE: A Self-Synthesis Method for Generating Large-Scale Alignment Data by Prompting Aligned LLMs with Nothing appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]