


Large language models (LLMs) face a significant challenge in accurately representing uncertainty over the correctness of their output. This issue is critical for decision-making applications, particularly in fields like healthcare where erroneous confidence can lead to dangerous outcomes. The task is further complicated by linguistic variances in freeform generation, which cannot be exhaustively accounted for during training. LLM practitioners must navigate the dichotomy between black-box and white-box estimation methods, with the former gaining popularity due to restricted models, while the latter becoming more accessible with open-source models.
Existing attempts to address this challenge explored various approaches. Some methods utilize LLMs’ natural expression of distribution over possible outcomes, using predicted token probabilities for multiple-choice tests. However, these become less reliable for sentence-length answers due to the need to spread probabilities over many phrasings. Other approaches utilize prompting to produce uncertainty estimates, capitalizing on LLMs’ learned concepts of “correctness” and probabilities. Linear probes have also been used to classify a model’s correctness based on hidden representations. Despite these efforts, black-box methods often fail to generate useful uncertainties for popular open-source models, necessitating careful fine-tuning interventions.
To advance the debate on necessary interventions for good calibration, researchers from New York University, Abacus AI, and Cambridge University have conducted a deep investigation into the uncertainty calibration of LLMs. They propose fine-tuning for better uncertainties, which provides faster and more reliable estimates while using relatively few additional parameters. This method shows promise in generalizing to new question types and tasks beyond the fine-tuning dataset. The approach involves teaching language models to recognize what they don’t know using a calibration dataset, exploring effective parameterization, and determining the amount of data required for good generalization.

The proposed method involves focusing on black-box techniques for estimating a language model’s uncertainty, particularly those requiring a single sample or forward pass. For an open-ended generation, where answers are not limited to individual tokens or prescribed possibilities, researchers use perplexity as a length-normalized metric. The approach also explores prompting methods as an alternative to sequence likelihood, introducing formats that lay the foundation for recent work. These include zero-shot classifiers and verbalized confidence statements, which are used to create uncertainty estimates from language model outputs.
Results show that fine-tuning for uncertainties significantly improves performance compared to commonly used baselines. The quality of black-box uncertainty estimates produced by open-source models was examined against accuracy, using models like LLaMA-2, Mistral, and LLaMA-3. Evaluation on open-ended MMLU revealed that prompting methods typically give poorly calibrated uncertainties, with calibration not improving out-of-the-box as the base model improves. However, AUROC showed slight improvement with the power of the underlying model, although still lagging behind models with fine-tuning for uncertainty.
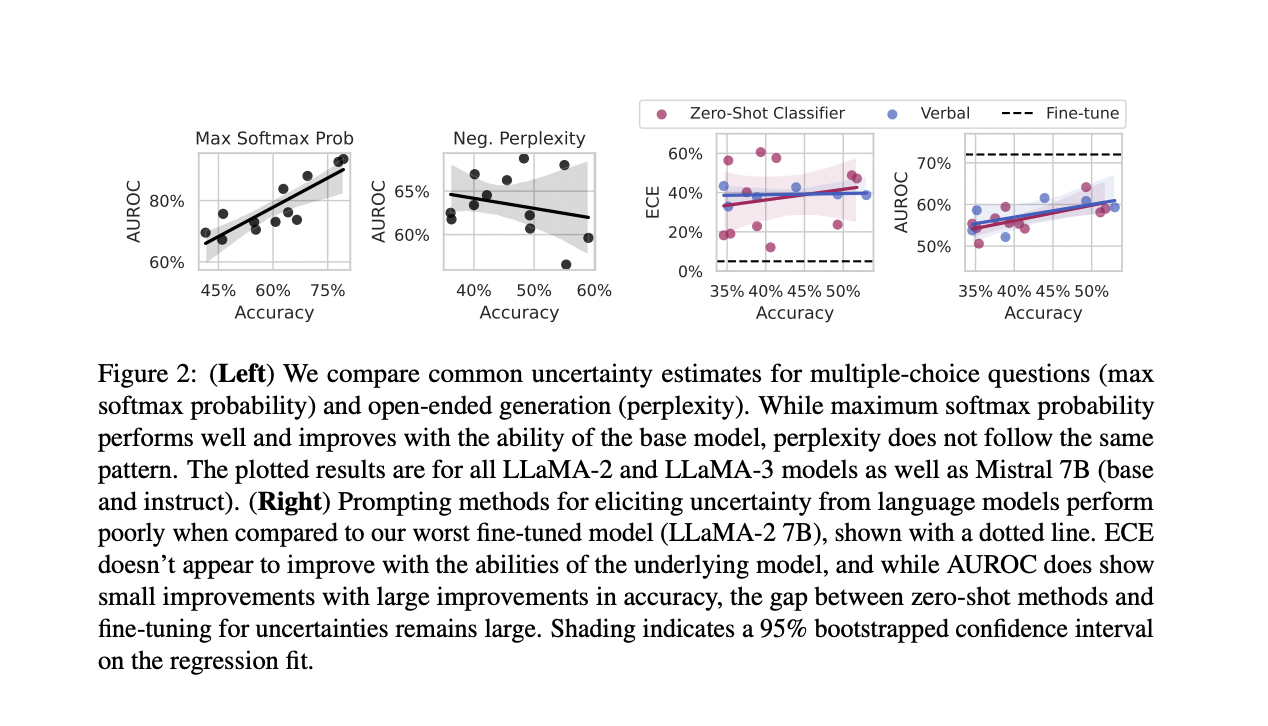
This study finds that out-of-the-box uncertainties from LLMs are unreliable for open-ended generation, contrary to prior results. The introduced fine-tuning procedures produce calibrated uncertainties with practical generalization properties. Notably, fine-tuning proves to be surprisingly sample-efficient and doesn’t rely on representations specific to a model evaluating its generations. The research also demonstrates the possibility of calibrated uncertainties being robust to distribution shifts.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 44k+ ML SubReddit
The post Enhancing Trust in Large Language Models: Fine-Tuning for Calibrated Uncertainties in High-Stakes Applications appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]