


Artificial intelligence (AI) is experiencing a paradigm shift, with breakthroughs driven by systems orchestrating multiple large language models (LLMs) and other complex components. This progression has highlighted the need for effective optimization methods for these compound AI systems, where automatic differentiation comes into play. Automatic differentiation has revolutionized the training of neural networks, and now researchers seek to apply similar principles to optimize more complex AI systems via textual feedback from LLMs.
One significant challenge in AI is optimizing compound systems that involve multiple components, such as LLMs, simulators, and web search tools. Traditional methods rely heavily on experts’ manual adjustments, which are time-consuming and prone to human error. Therefore, there is a pressing need for principled and automated optimization methods that can handle the complexity and variability of these systems.
Existing research includes frameworks like DSPy, which optimizes LLM-based systems programmatically, and ProTeGi, which uses textual gradients for prompt optimization. DSPy enhances LLM performance in various tasks by structuring complex systems as layered programs. ProTeGi focuses on improving prompts through natural language feedback. These methods automate the optimization process but are limited to specific applications. TEXTGRAD, inspired by these approaches, expands the use of textual gradients to broader optimization tasks, integrating LLMs’ reasoning capabilities across diverse domains.
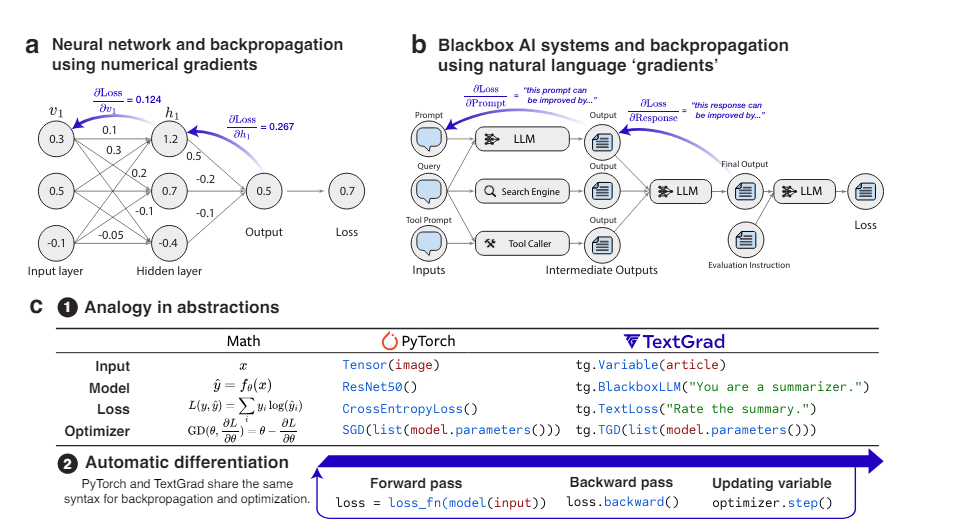
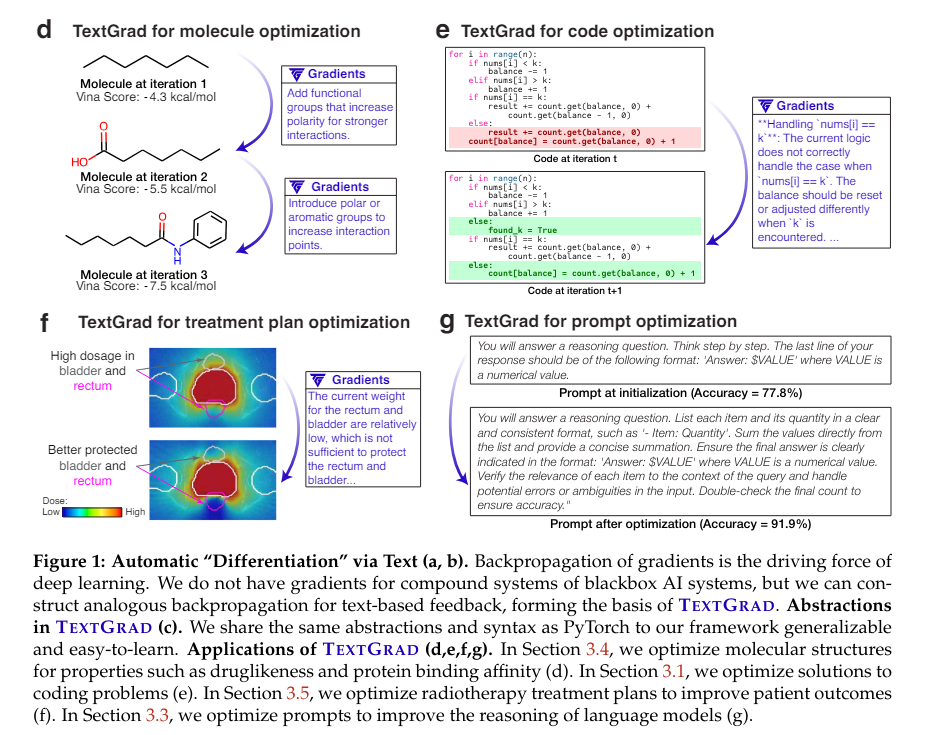
Researchers from Stanford University and the Chan Zuckerberg Biohub have introduced TEXTGRAD, a framework that performs automatic differentiation via text, using feedback from LLMs to optimize AI systems. TEXTGRAD converts each AI system into a computation graph, where variables are inputs and outputs of complex functions. It leverages the rich, interpretable natural language feedback provided by LLMs to generate “textual gradients,” which describe how variables should be adjusted to improve system performance. This innovative approach makes TEXTGRAD flexible and easy to use, as users only need to provide the objective function without tuning components or prompts.
TEXTGRAD employs LLMs to generate detailed feedback for various tasks, making the framework applicable across multiple domains. For instance, in the field of coding, TEXTGRAD improved the performance of AI models on difficult coding problems from the LeetCode platform. By identifying edge cases that caused failures in initial solutions, TEXTGRAD provided suggestions for improvement, leading to a 20% relative performance gain. In question-answering tasks, TEXTGRAD enhanced the zero-shot accuracy of GPT-4 in the Google-Proof Question Answering benchmark from 51% to 55%. The framework also designed new drug-like molecules with desirable properties, significantly improving binding affinity and drug-likeness metrics.
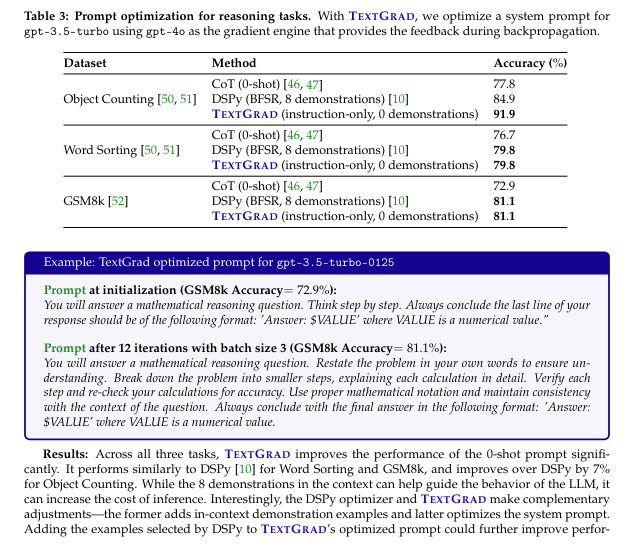
TEXTGRAD’s results speak for themselves. In coding optimization, it improved the success rate of GPT-4 from 7% to 23% in a zero-shot setting and from 15% to 31% when using Reflexion. In problem-solving tasks, it boosted the accuracy of GPT-4 in the Google-Proof Question Answering benchmark to 55%, the highest known result for this dataset. For the Multi-Task Language Understanding (MMLU) benchmark, it increased the accuracy from 85.7% to 88.4% in the Machine Learning subset and from 91.2% to 95.1% in the College Physics subset. These impressive results underscore the effectiveness of TEXTGRAD in improving AI performance.
TEXTGRAD optimized molecules for better binding affinity and drug-likeness in chemistry, demonstrating its versatility in multi-objective optimization tasks. The framework generated molecules with high binding affinities and favorable drug-likeness scores comparable to clinically approved drugs. In medical applications, TEXTGRAD improved radiotherapy treatment plans by optimizing hyperparameters to target tumors better while minimizing damage to healthy tissues. The framework’s ability to provide meaningful guidance through textual gradients resulted in treatment plans that met clinical goals more effectively than traditional methods.
In conclusion, TEXTGRAD represents a significant advancement in AI optimization, leveraging the capabilities of LLMs to provide detailed, natural language feedback. This approach enables efficient and effective optimization of complex AI systems, paving the way for developing next-generation AI technologies. Researchers from Stanford University and the Chan Zuckerberg Biohub have demonstrated that TEXTGRAD’s flexibility and ease of use make it a powerful tool for enhancing AI performance across various domains. By automating the optimization process, TEXTGRAD reduces the reliance on manual adjustments, accelerating the progress of AI research and applications.
The post Researchers at Stanford Introduce TEXTGRAD: A Powerful AI Framework Performing Automatic “Differentiation” via Text appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]