


Deploying large language models (LLMs) on resource-constrained devices presents significant challenges due to their extensive parameters and reliance on dense multiplication operations. This results in high memory demands and latency bottlenecks, hindering their practical application in real-world scenarios. For instance, models like GPT-3 require immense computational resources, making them unsuitable for many edge and cloud environments. Overcoming these challenges is crucial for the advancement of AI, as it would enable the efficient deployment of powerful LLMs, thereby broadening their applicability and impact.
Current methods to enhance the efficiency of LLMs include pruning, quantization, and attention optimization. Pruning techniques reduce model size by removing less significant parameters, but this often leads to accuracy loss. Quantization, particularly post-training quantization (PTQ), reduces the bit-width of weights and activations to lower memory and computation demands. However, existing PTQ methods either require significant retraining or lead to accuracy degradation due to quantization errors. Additionally, these methods still rely heavily on costly multiplication operations, limiting their effectiveness in reducing latency and energy consumption.
Researchers from Google, Intel, and Georgia Institute of Technology propose ShiftAddLLM, a method that accelerates pre-trained LLMs through post-training shift-and-add reparameterization. This approach replaces traditional multiplications with hardware-friendly shift and add operations. Specifically, it quantizes weight matrices into binary matrices with group-wise scaling factors. These multiplications are then reparameterized into shifts between activations and scaling factors, and queries and adds based on the binary matrices. This method addresses the limitations of existing quantization techniques by minimizing both weight and activation reparameterization errors through a multi-objective optimization framework. This innovative approach significantly reduces memory usage and latency while maintaining or improving model accuracy.
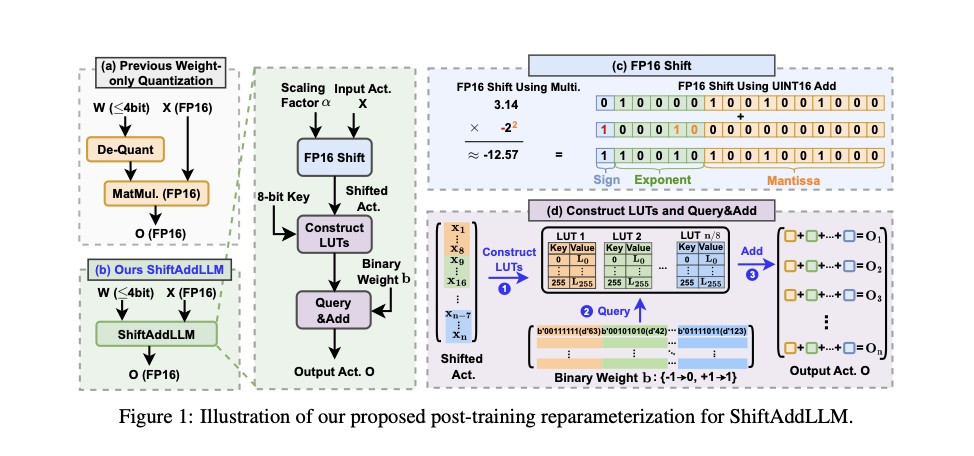
ShiftAddLLM employs a multi-objective optimization method to align weight and output activation objectives, minimizing overall reparameterization errors. The researchers introduced an automated bit allocation strategy, optimizing the bit-widths for weights in each layer based on their sensitivity to reparameterization. This strategy ensures that more sensitive layers receive higher-bit representations, thus avoiding accuracy loss while maximizing efficiency. The proposed method is validated across five LLM families and eight tasks, showing average perplexity improvements of 5.6 and 22.7 points at comparable or lower latency compared to the best existing quantized LLMs. Additionally, ShiftAddLLM achieves over 80% reductions in memory and energy consumption.
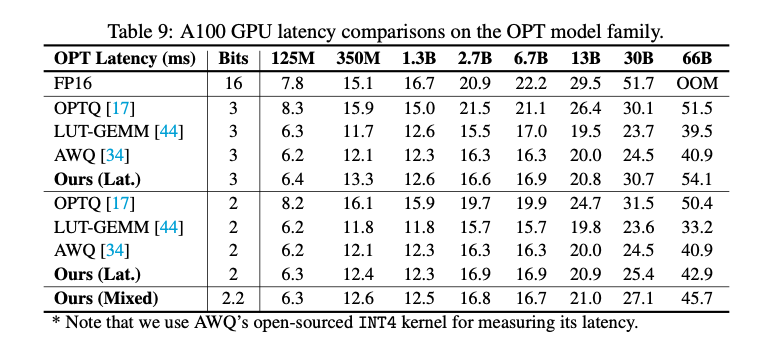
The experimental results demonstrate the effectiveness of ShiftAddLLM. Significant improvements in perplexity scores across various models and tasks were reported. For example, ShiftAddLLM achieves perplexity reductions of 5.63/38.47/5136.13 compared to OPTQ, LUT-GEMM, and AWQ at 3 bits, respectively. In 2-bit settings, where most baselines fail, ShiftAddLLM maintains low perplexity and achieves an average reduction of 22.74 perplexity points over the most competitive baseline, QuIP. The method also shows better accuracy-latency trade-offs, with up to 103830.45 perplexity reduction and up to 60.1% latency reductions. The below key result table compares perplexity scores and latencies of various methods, highlighting ShiftAddLLM’s superior performance in both metrics.
In conclusion, the researchers present ShiftAddLLM, a significant advancement in the efficient deployment of LLMs. The method reparameterizes weight matrices into shift-and-add operations, drastically reducing computational costs while maintaining high accuracy. This innovation is achieved through a multi-objective optimization strategy and an automated bit allocation approach. ShiftAddLLM offers substantial improvements in memory and energy efficiency, demonstrating its potential to make advanced LLMs more accessible and practical for a wider range of applications. This work represents a critical step forward in addressing the deployment challenges of large-scale AI models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 44k+ ML SubReddit
The post ShiftAddLLM: Accelerating Pretrained LLMs through Post-Training Shift-and-Add Reparameterization: Creating Efficient Multiplication-Free Models appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]