


Generative AI has made remarkable progress in revolutionizing fields like image and video generation, driven by innovative algorithms, architectures, and data. However, the rapid proliferation of generative models has highlighted a critical gap: the absence of trustworthy evaluation metrics. Current automatic assessments such as FID, CLIP, and FVD often fail to capture the nuanced quality and user satisfaction associated with generative outputs. While image generation and manipulation technologies have advanced rapidly, enabling applications across domains like art, visual enhancement, and medical imaging, navigating the multitude of available models and assessing their performance remains challenging. Traditional metrics like PSNR, SSIM, LPIPS, and FID provide valuable but specific insights into precise aspects of visual content generation, often falling short in comprehensively evaluating overall model performance, especially regarding subjective qualities like aesthetics and user satisfaction.
Numerous methods have been proposed to evaluate the performance of multimodal generative models across various aspects. For image generation, methods like CLIPScore measure text-alignment, while IS, FID, PSNR, SSIM, and LPIPS assess image fidelity and perceptual similarity. Recent works use multimodal large language models (MLLMs) as judges, such as T2I-CompBench using miniGPT4, TIFA adapting visual question answering, and VIEScore reporting MLLMs’ potential to replace human judges. For video generation, metrics like FVD measure frame coherence and quality, while CLIPSIM utilizes image-text similarity models. However, these automatic metrics still lag behind human preferences, with low correlation raising doubts about their reliability. Generative AI evaluation platforms aim to systematically rank models, with benchmark suites like T2ICompBench, HEIM, ImagenHub for images, and VBench, EvalCrafter for videos. Despite functionality, these benchmarks rely on model-based metrics less reliable than human evaluation. Model arenas have emerged to collect direct human preferences for ranking, but no existing arena focuses specifically on generative AI models.
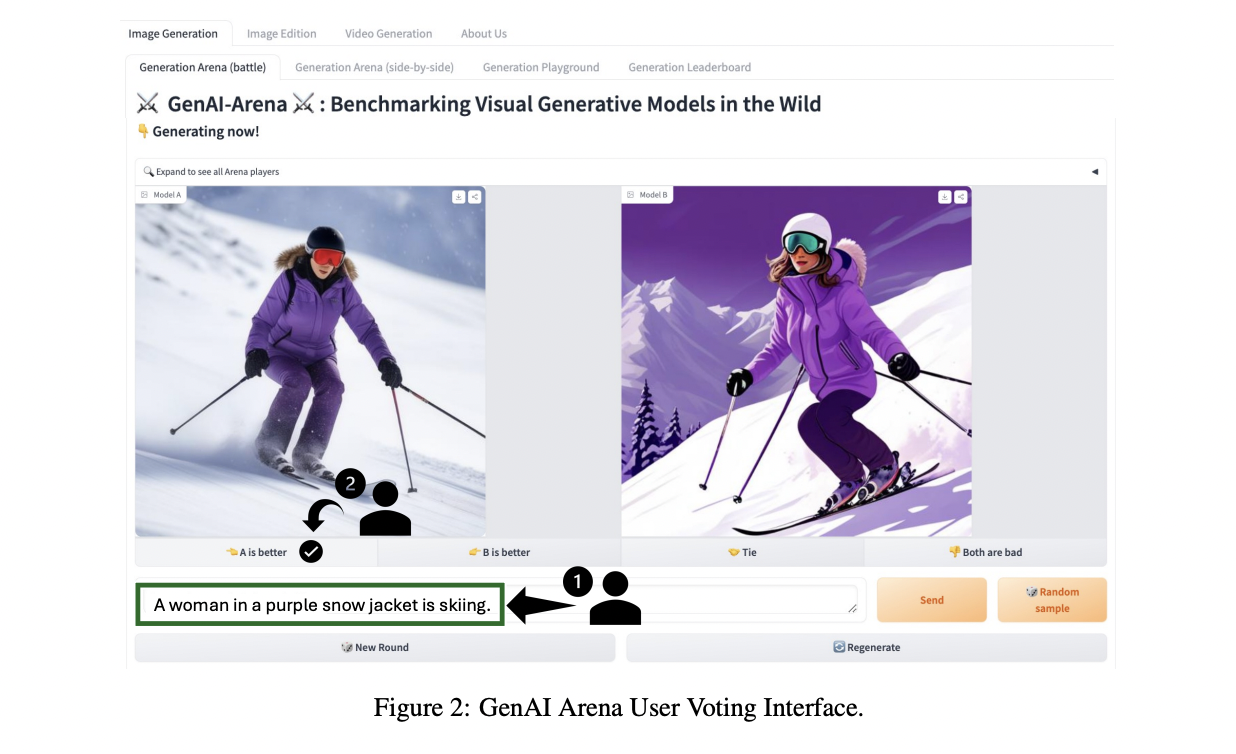
The researchers from the University of Waterloo have introduced GenAI-Arena, a robust platform designed to enable fair evaluation of generative AI models. Inspired by successful implementations in other domains, GenAI-Arena offers a dynamic and interactive platform where users can generate images, compare them side-by-side, and vote for their preferred models. This platform simplifies the process of comparing different models and provides a ranking system that reflects human preferences, offering a more holistic evaluation of model capabilities. GenAI-Arena is the first evaluation platform with comprehensive evaluation capabilities across multiple properties, supporting a wide range of tasks including text-to-image generation, text-guided image editing, and text-to-video generation, along with a public voting process to ensure labeling transparency. The votes are utilized to assess the evaluation ability of MLLM evaluators. The platform excels in its versatility and transparency. It has collected over 6000 votes for three multimodal generative tasks and it has constructed leaderboards for each task, identifying the state-of-the-art models.

GenAI-Arena supports text-to-image generation, image editing, and text-to-video generation tasks with features like anonymous side-by-side voting, battle playground, direct generation tab, and leaderboards. The platform standardizes model inference with fixed hyper-parameters and prompts for fair comparison. It enforces unbiased voting through anonymity, where users vote their preferences between anonymously generated outputs, calculating Elo rankings. This architecture allows for a democratic, accurate assessment of model performance across multiple tasks.
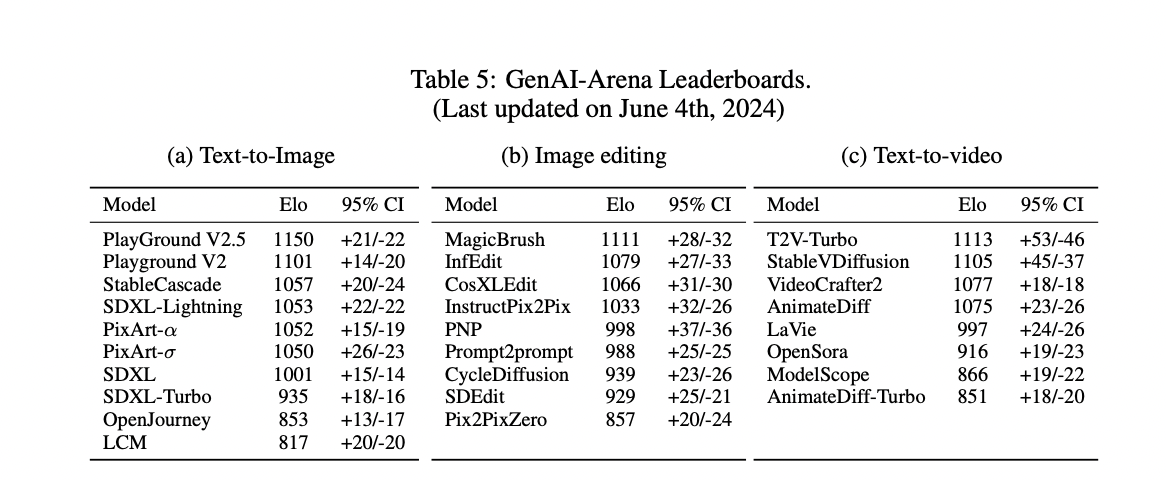
The researchers report their leaderboard ranking at the time of writing. For image generation with 4443 votes collected, Playground V2.5 and Playground V2 models from Playground.ai top the ranks, following the same SDXL architecture but trained on a private dataset, significantly outperforming the 7th-ranked SDXL which highlights the importance of training data. StableCascade utilizing an efficient cascade architecture ranks next, beating SDXL despite only 10% of SD-2.1’s training cost, underscoring the importance of diffusion architecture. For image editing with 1083 votes, MagicBrush, InFEdit, CosXLEdit, and InstructPix2Pix enabling localized editing rank higher, while older methods like Prompt-to-Prompt producing completely different images rank lower despite high-quality outputs. In text-to-video with 1568 votes, T2VTurbo leads with the highest Elo score as the most effective model, followed closely by StableVideoDiffusion, VideoCrafter2, AnimateDiff, and others like LaVie, OpenSora, ModelScope with decreasing performance.
In this study, GenAI-Arena, an open platform driven by community voting is introduced to rank generative models across text-to-image, image editing, and text-to-video tasks based on user preferences for transparency. Over 6000 votes collected from February to June 2024 were used to compile Elo leaderboards, identifying state-of-the-art models while analysis revealed potential biases. The high-quality human preference data was released as GenAI-Bench, exposing the poor correlation of existing multimodal language models with human judgments on generated content quality and other aspects.
Check out the Paper and HF Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 44k+ ML SubReddit
The post GenAI-Arena: An Open Platform for Community-Based Evaluation of Generative AI Models appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]