


The training of Large Language Models (LLMs) like GPT-3 and Llama on a large scale faces significant inefficiencies due to hardware failures and network congestion. These issues lead to substantial GPU resource waste and extended training durations. Specifically, hardware malfunctions cause interruptions in training, and network congestions force GPUs to wait for parameter synchronization, further delaying the training process. Addressing these challenges is crucial for advancing AI research, as it directly affects the efficiency and feasibility of training highly complex models.

Current methods to tackle these challenges involve basic fault tolerance and traffic management strategies. These include using redundant computations, erasure coding for storage reliability, and multi-path strategies to handle network anomalies. However, these methods have significant limitations. They are not efficient in real-time applications due to their computational complexity and extensive manual intervention requirements for fault diagnosis and isolation. Additionally, these methods often fail to manage network traffic effectively in shared physical clusters, leading to congestion and reduced performance scalability.
The researchers From the Alibaba group propose a novel approach named C4 (Calibrating Collective Communication over Converged Ethernet), designed to address the inefficiencies of current methods by focusing on enhancing communication efficiency and fault tolerance in large-scale AI clusters. C4 consists of two subsystems: C4D (C4 Diagnosis) and C4P (C4 Performance). C4D improves training stability by detecting system errors in real time, isolating faulty nodes, and facilitating quick restarts from the last checkpoint. C4P optimizes communication performance by efficiently managing network traffic, thereby reducing congestion and improving GPU utilization. This approach represents a significant contribution to the field by offering a more efficient and accurate solution compared to existing methods.
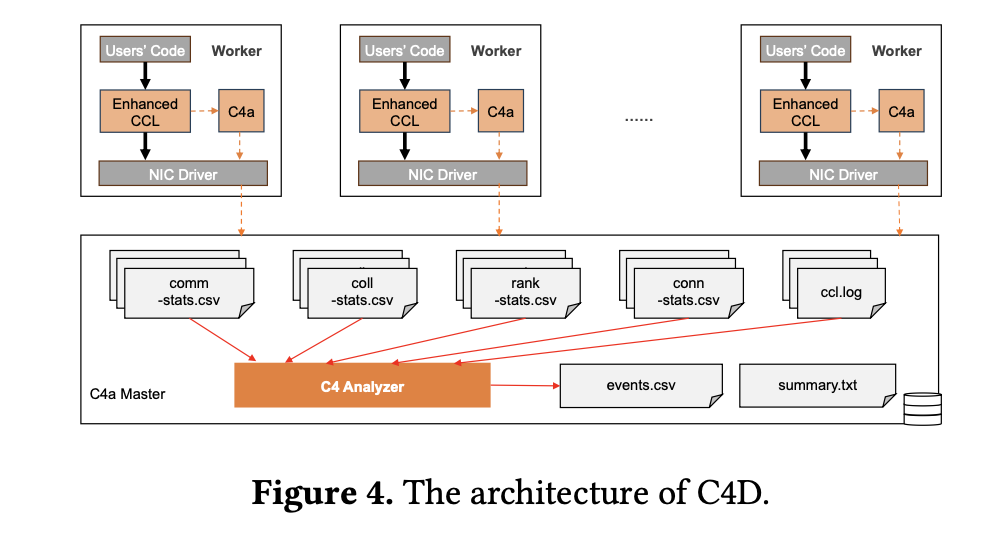
The C4 system leverages the predictable communication patterns of collective operations in parallel training to implement its solutions. C4D enhances the collective communication library to monitor operations and detect potential errors based on anomalies in the homogeneous characteristics of collective communication. Once a suspect node is identified, it is isolated and the task is restarted, minimizing downtime. C4P employs traffic engineering techniques to optimize the distribution of network traffic, balancing the load across multiple paths and dynamically adjusting to network changes. The system’s deployment across large-scale AI training clusters has shown to cut error-induced overhead by approximately 30% and enhance runtime performance by about 15%.
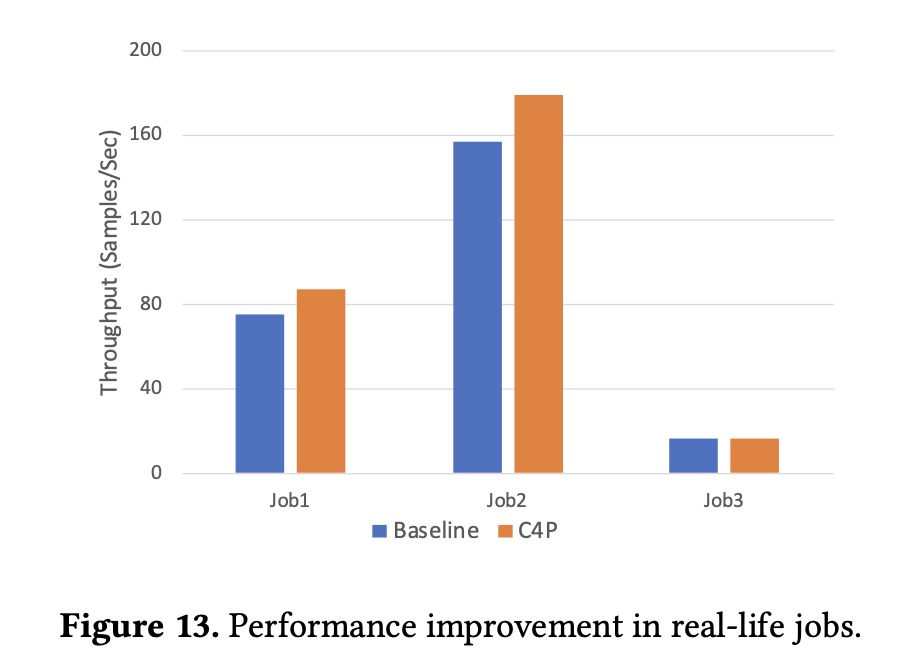
The researchers evaluated the effectiveness of C4 by focusing on key performance metrics such as throughput and error reduction. For instance, the figure below from the paper highlights the performance improvement across three representative training jobs, showing that C4P increases throughput by up to 15.95% for tasks with high communication overhead. The table compares different methods, including the proposed C4 approach, with existing baselines, highlighting the significant improvement in efficiency and error handling.
In conclusion, the proposed methods provide a comprehensive solution to the inefficiencies in large-scale AI model training. The C4 system, with its subsystems C4D and C4P, addresses critical challenges in fault detection and network congestion, offering a more efficient and accurate method for training LLMs. By significantly reducing error-induced overhead and improving runtime performance, these methods advance the field of AI research, making high-performance model training more practical and cost-effective.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 44k+ ML SubReddit
The post Enhancing Large-scale Parallel Training Efficiency with C4 by Alibaba appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #Staff #TechNews #Technology [Source: AI Techpark]