


Audio classification has evolved significantly with the adoption of deep learning models. Initially dominated by Convolutional Neural Networks (CNNs), this field has shifted towards transformer-based architectures, which offer improved performance and the ability to handle various tasks through a unified approach. Transformers surpass CNNs in performance, creating a paradigm shift in deep learning, especially for functions requiring extensive contextual understanding and handling diverse input data types.
The primary challenge in audio classification is the computational complexity associated with transformers, particularly due to their self-attention mechanism, which scales quadratically with the sequence length. This makes it inefficient for processing long audio sequences, necessitating alternative methods to maintain performance while reducing computational load. Addressing this issue is crucial for developing models that can efficiently handle audio data’s increasing volume and complexity in various applications, from speech recognition to environmental sound classification.
Currently, the most prominent method for audio classification is the Audio Spectrogram Transformer (AST). ASTs utilize self-attention mechanisms to capture the global context in audio data but suffer from high computational costs. State space models (SSMs) have been explored as a potential alternative, offering linear scaling with sequence length. SSMs, such as Mamba, have shown promise in language and vision tasks by replacing self-attention with time-varying parameters to capture global context more efficiently. Despite their success in other domains, SSMs have yet to be widely adopted in audio classification, presenting an opportunity for innovation in this area.

Researchers from the Korea Advanced Institute of Science and Technology introduced Audio Mamba (AuM), a novel self-attention-free model based on state space models for audio classification. This model processes audio spectrograms efficiently using a bidirectional approach to handle long sequences without the quadratic scaling associated with transformers. The AuM model aims to eliminate the computational burden of self-attention, leveraging SSMs to maintain high performance while improving efficiency. By addressing the inefficiencies of transformers, AuM offers a promising alternative for audio classification tasks.
Audio Mamba’s architecture involves converting input audio waveforms into spectrograms, which are then divided into patches. These patches are transformed into embedding tokens and processed using bidirectional state space models. The model operates in both forward and backward directions, capturing the global context efficiently and maintaining linear time complexity, thus improving processing speed and memory usage compared to ASTs. The architecture incorporates several innovative design choices, such as the strategic placement of a learnable classification token in the middle of the sequence and the use of positional embeddings to enhance the model’s ability to understand the spatial structure of the input data.
Audio Mamba demonstrated competitive performance across various benchmarks, including AudioSet, VGGSound, and VoxCeleb. The model achieved comparable or better results than AST, particularly excelling in tasks involving long audio sequences. For example, in the VGGSound dataset, Audio Mamba outperformed AST with a substantial accuracy improvement of over 5%, achieving 42.58% accuracy compared to AST’s 37.25%. On the AudioSet dataset, AuM achieved a mean average precision (mAP) of 32.43%, surpassing AST’s 29.10%. These results highlight AuM’s ability to deliver high performance while maintaining computational efficiency, making it a robust solution for various audio classification tasks.
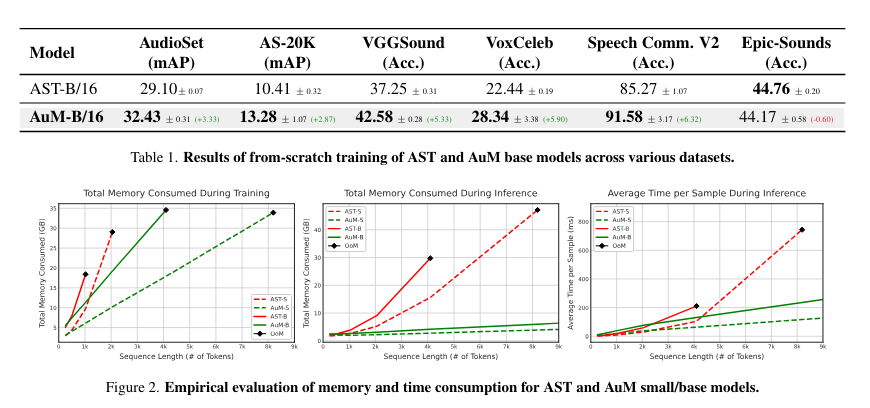
The evaluation showed that AuM requires significantly less memory and processing time. For instance, during training with 20-second audio clips, AuM consumed memory equivalent to AST’s smaller model while delivering superior performance. Furthermore, AuM’s inference time was 1.6 times faster than AST’s at a token count 4096, demonstrating its efficiency in handling long sequences. This reduction in computational requirements without compromising accuracy indicates that AuM is well-suited for real-world applications where resource constraints are a critical consideration.
In summary, the introduction of Audio Mamba marks a significant advancement in audio classification by addressing the limitations of self-attention in transformers. The model’s efficiency and competitive performance highlight its potential as a viable alternative for processing long audio sequences. Researchers believe that Audio Mamba’s approach could pave the way for future audio and multimodal learning applications developments. The ability to handle lengthy audio is increasingly crucial, especially with the rise of self-supervised multimodal learning and generation that leverages in-the-wild data and automatic speech recognition. Furthermore, AuM could be employed in self-supervised learning setups like Audio Masked Auto Encoders or multimodal learning tasks such as Audio-Visual pretraining or Contrastive Language-Audio Pretraining, contributing to the advancement of the audio classification field.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 43k+ ML SubReddit | Also, check out our AI Events Platform
The post Taming Long Audio Sequences: Audio Mamba Achieves Transformer-Level Performance Without Self-Attention appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #Sound #Staff #Technology [Source: AI Techpark]