


Nomic AI has recently unveiled two significant releases in multimodal embedding models: Nomic Embed Vision v1 and Nomic Embed Vision v1.5. These models are designed to provide high-quality, fully replicable vision embeddings that seamlessly integrate with the existing Nomic Embed Text v1 and v1.5 models. This integration creates a unified embedding space that enhances the performance of multimodal and text tasks, outperforming competitors like OpenAI CLIP and OpenAI Text Embedding 3 Small.
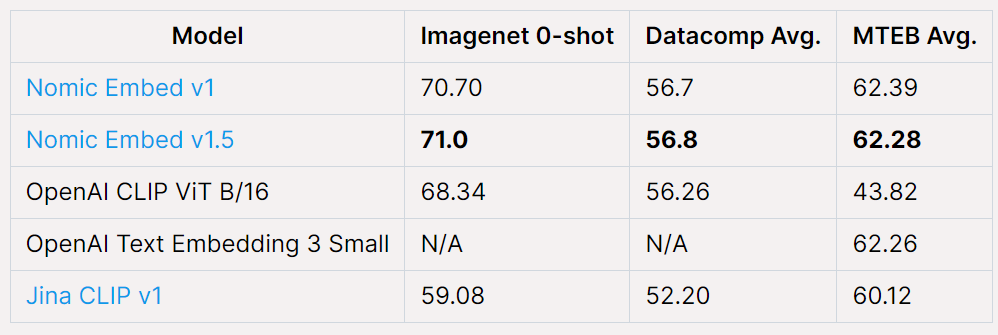
Nomic Embed Vision aims to address the limitations of existing multimodal models such as CLIP, which, while impressive in zero-shot multimodal capabilities, underperform tasks outside image retrieval. By aligning a vision encoder with the existing Nomic Embed Text latent space, Nomic has created a unified multimodal latent space that excels in image and text tasks. This unified space has shown superior performance on benchmarks like Imagenet 0-Shot, MTEB, and Datacomp, making it the first weights model to achieve such results.
Nomic Embed Vision models can embed image and text data, perform an unimodal semantic search within datasets, and conduct a multimodal semantic search across datasets. With just 92M parameters, the vision encoder is ideal for high-volume production use cases, complementing the 137M Nomic Embed Text. Nomic has open-sourced the training code and replication instructions, allowing researchers to reproduce and enhance the models.
The performance of these models is benchmarked against established standards, with Nomic Embed Vision demonstrating superior performance on various tasks. For instance, Nomic Embed v1 achieved 70.70 on Imagenet 0-shot, 56.7 on Datacomp Avg., and 62.39 on MTEB Avg. Nomic Embed v1.5 performed slightly better, indicating the robustness of these models.
Nomic Embed Vision powers multimodal search in Atlas, showcasing its ability to understand textual queries and image content. An example query demonstrated the model’s semantic understanding by retrieving images of cuddly animals from a dataset of 100,000 images and captions.
Training Nomic Embed Vision involved several innovative approaches to align the vision encoder with the text encoder. These included training on image-text pairs and text-only data, using a Three Towers training method, and Locked-Image Text Tuning. The most effective approach involved freezing the text encoder and training the vision encoder on image-text pairs, ensuring backward compatibility with Nomic Embed Text embeddings.
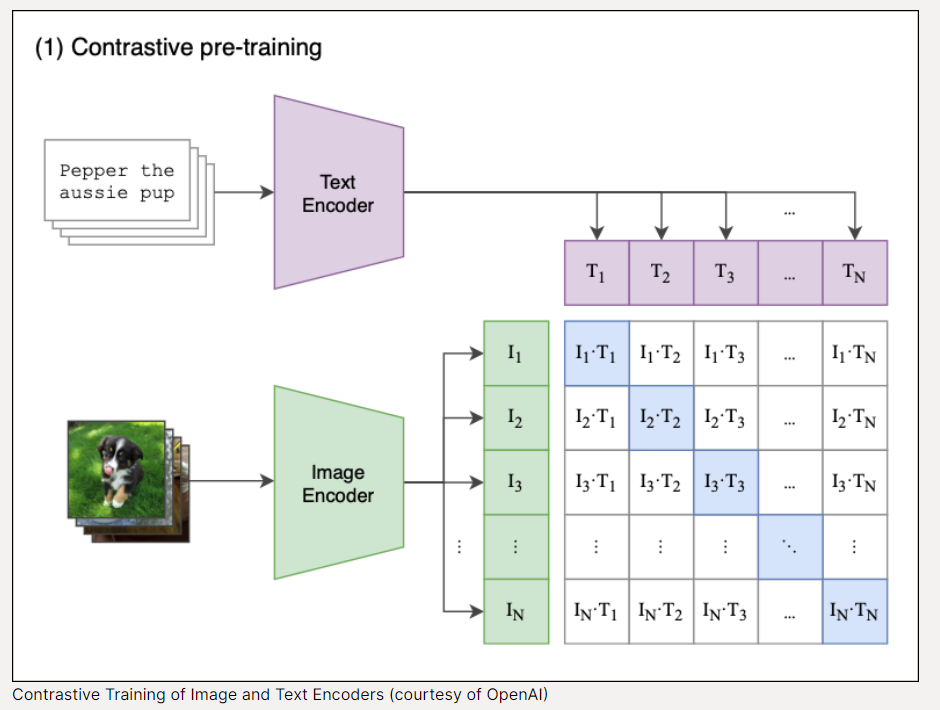
The vision encoder was trained on a subset of 1.5 billion image-text pairs using 16 H100 GPUs, achieving impressive results on the Datacomp benchmark, which includes 38 image classification and retrieval tasks.
Nomic has released two versions of Nomic Embed Vision, v1 and v1.5, which are compatible with the corresponding versions of Nomic Embed Text. This compatibility allows for seamless multimodal tasks across different versions. The models are released under a CC-BY-NC-4.0 license, encouraging experimentation and research, with plans to re-license under Apache-2.0 for commercial use.
In conclusion, Nomic Embed Vision v1 and v1.5 transform multimodal embeddings, providing a unified latent space that excels in image and text tasks. With open-source training codes and a commitment to ongoing innovation, Nomic AI sets a new standard in embedding models, offering powerful tools for various applications.
The post Nomic AI Releases Nomic Embed Vision v1 and Nomic Embed Vision v1.5: CLIP-like Vision Models that Can be Used Alongside their Popular Text Embedding Models appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]