


Machine learning has seen significant advancements, with Transformers emerging as a dominant architecture in language modeling. These models have revolutionized natural language processing by enabling machines to understand and generate human language accurately. The efficiency and scalability of these models remain a significant challenge, particularly due to the quadratic scaling of traditional attention mechanisms with the sequence length. Researchers aim to address this by exploring alternative methods to maintain performance while enhancing efficiency.
A key challenge in this field is to improve the efficiency and scalability of these models. Traditional attention mechanisms used in Transformers scale quadratically with the sequence length, posing limitations for long sequences. Researchers aim to address this by exploring alternative methods to maintain performance while enhancing efficiency. One such challenge is the significant computational demand and memory usage associated with traditional attention mechanisms, which restricts the effective handling of longer sequences.
Existing work includes Structured State Space Models (SSMs), which offer linear scaling during training and constant state size during generation, making them suitable for long-range tasks. However, integrating these models into existing deep-learning frameworks remains challenging due to their unique structure and optimization requirements. SSMs have demonstrated strong performance in tasks requiring long-range dependencies but need help in integration and optimization within established deep-learning frameworks.
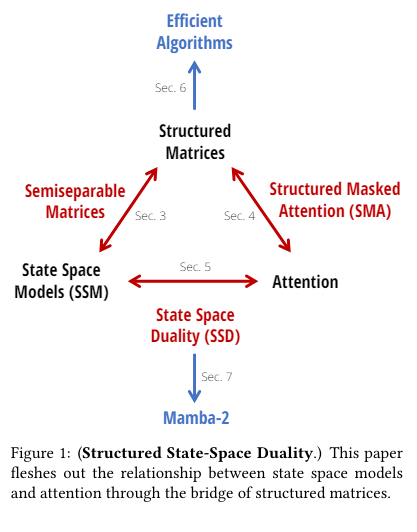
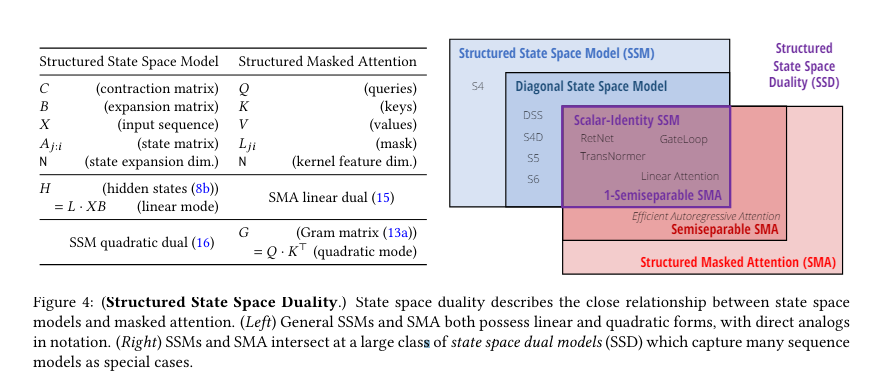
Researchers from Princeton University and Carnegie Mellon University have introduced the State Space Duality (SSD) framework, which connects SSMs and attention mechanisms. This new architecture, Mamba-2, refines the selective SSM, achieving speeds 2-8 times faster than its predecessor while maintaining competitive performance with Transformers. Mamba-2 leverages the efficiency of matrix multiplication units in modern hardware to optimize training and inference processes. The SSD framework allows the exploitation of specialized matrix multiplication units, significantly enhancing computation speeds and efficiency.
The core of Mamba-2’s design involves a series of efficient algorithms that exploit the structure of semi separable matrices. These matrices allow optimal computing, memory usage, and scalability trade-offs, significantly enhancing the model’s performance. The research team employed a variety of techniques to refine Mamba-2, including the use of matrix multiplication units on GPUs, which are known as tensor cores. These tensor cores significantly speed up the computation process. Furthermore, to improve efficiency, the model integrates grouped-value attention and tensor parallelism, techniques borrowed from Transformer optimizations. The Mamba-2 architecture also utilizes selective SSMs, which can dynamically choose to focus on or ignore inputs at every timestep, allowing for better information retention and processing. The training setup follows the GPT-3 specifications, using the Pile dataset and adhering to the training recipes from prior models. These innovations collectively ensure that Mamba-2 balances computational and memory efficiency while maintaining high performance, making it a robust tool for language modeling tasks.
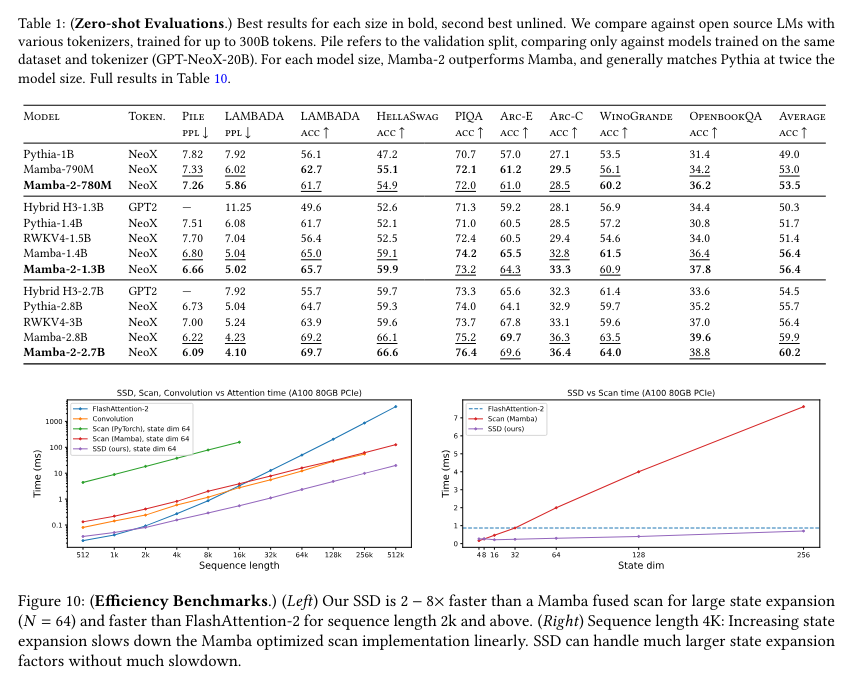
The performance of Mamba-2 is validated through various benchmarks, demonstrating its superiority over previous models. It achieves better perplexity and wall-clock time, making it a robust alternative for language modeling tasks. For instance, Mamba-2, with 2.7B parameters trained on 300B tokens, outperforms its predecessor and other models like Pythia-2.8B and Pythia-6.9B on standard downstream evaluations. The model achieves notable results, including lower perplexity scores and faster training times, validating its effectiveness in real-world applications.
In terms of specific performance metrics, Mamba-2 shows significant improvements. It achieves a perplexity score 6.09 on the Pile dataset, compared to 6.13 for the original Mamba model. Moreover, Mamba-2 exhibits faster training times, being 2-8 times quicker due to its efficient use of tensor cores for matrix multiplication. These results highlight the model’s efficiency in handling large-scale language tasks, making it a promising tool for future advancements in natural language processing.
In conclusion, the research introduces an innovative method that bridges the gap between SSMs and attention mechanisms, offering a scalable and efficient solution for language modeling. This advancement not only enhances performance but also paves the way for future developments in the field. Introducing the SSD framework and the Mamba-2 architecture provides a promising direction for overcoming the limitations of traditional attention mechanisms in Transformers.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 43k+ ML SubReddit | Also, check out our AI Events Platform
The post Beyond Quadratic Bottlenecks: Mamba-2 and the State Space Duality Framework for Efficient Language Modeling appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]