


Scale AI has announced the launch of SEAL Leaderboards, an innovative and expert-driven ranking system for large language models (LLMs). This initiative is a product of the Safety, Evaluations, and Alignment Lab (SEAL) at Scale, which is dedicated to providing neutral, trustworthy evaluations of AI models. The SEAL Leaderboards aim to address the growing need for reliable performance comparisons as LLMs become more advanced and widely utilized.
With hundreds of LLMs, comparing their performance and safety has become increasingly challenging. Scale, a trusted third-party evaluator for leading AI labs, has developed the SEAL Leaderboards to rank frontier LLMs using curated private datasets that cannot be manipulated. These evaluations are conducted by verified domain experts, ensuring the rankings are unbiased and provide a true measure of model performance.
The SEAL Leaderboards initially cover several critical domains, including:
- Coding
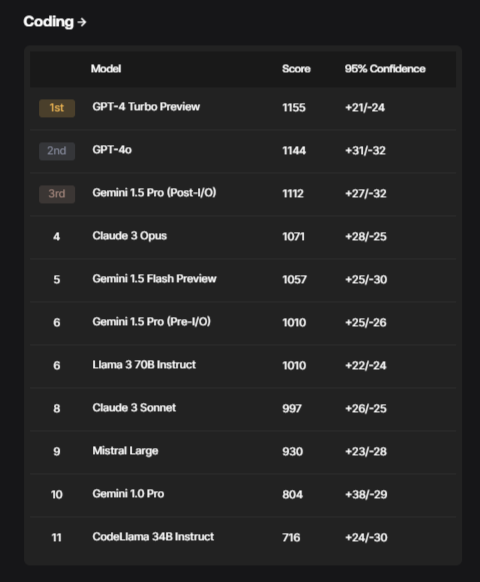
- Instruction Following
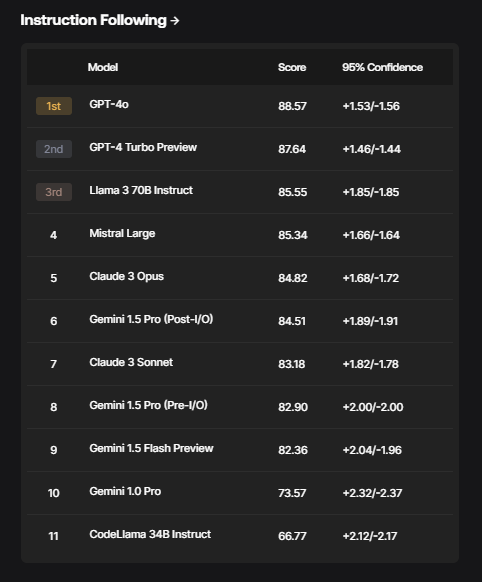
- Math (based on GSM1k)
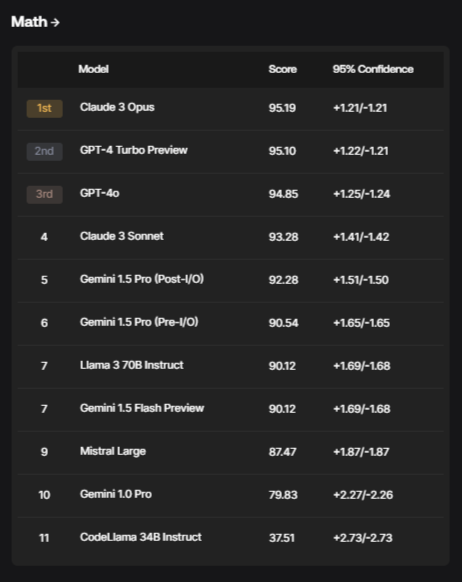
- Multilinguality
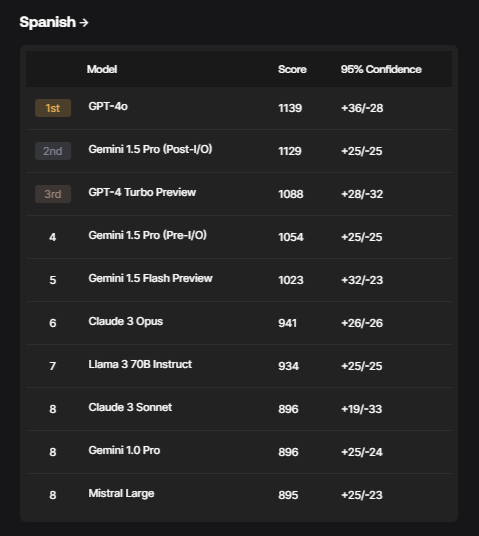
Each domain features prompt sets created from scratch by experts, tailored to evaluate performance in that specific area best. The evaluators are rigorously vetted, ensuring they possess the necessary domain-specific expertise.
To maintain the integrity of the evaluations, Scale’s datasets remain private and unpublished, preventing them from being exploited or included in model training data. The SEAL Leaderboards limit entries from developers who might have accessed the specific prompt sets, ensuring unbiased results. Scale collaborates with trusted third-party organizations to review their work, adding another layer of accountability.
Scale’s SEAL research lab, launched last November, is uniquely positioned to tackle several persistent challenges in AI evaluation:
- Contamination and Overfitting: Ensuring high-quality, uncontaminated evaluation datasets.
- Inconsistent Reporting: Standardizing model comparisons and reliability of evaluation results.
- Unverified Expertise: Rigorous assessment of evaluators’ expertise in specific domains.
- Inadequate Tooling: Providing robust tools for understanding and iterating on evaluation results without overfitting.
These efforts aim to enhance AI model evaluations’ overall quality, transparency, and standardization.
Scale plans to continuously update the SEAL Leaderboards with new prompt sets and frontier models as they become available, refreshing the rankings multiple times a year to reflect the latest advancements in AI. This commitment ensures that the leaderboards remain relevant and up-to-date, driving improved evaluation standards across the AI community.
In addition to the leaderboards, Scale has announced the general availability of Scale Evaluation, a platform designed to help AI researchers, developers, enterprises, and public sector organizations analyze, understand, and improve their AI models and applications. This platform marks a step forward in Scale’s mission to accelerate AI development through rigorous, independent evaluations.
The post Scale AI’s SEAL Research Lab Launches Expert-Evaluated and Trustworthy LLM Leaderboards appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]