


Recent years have seen significant advances in neural language models, particularly Large Language Models (LLMs) enabled by the Transformer architecture and increased scale. LLMs exhibit exceptional skills in generating grammatical text, answering questions, summarising content, creating imaginative outputs, and solving complex puzzles. A key capability is in-context learning (ICL), where the model uses novel task exemplars presented during inference to respond accurately without weight updates. ICL is typically attributed to Transformers and their attention-based mechanisms.
ICL has been shown for linear regression tasks with Transformers, which can generalize to new input/label pairs in-context. Transformers achieve this by potentially implementing gradient descent or replicating least-squares regression. Transformers interpolate between in-weight learning (IWL) and ICL, with diverse datasets enhancing ICL capabilities. While most studies focus on Transformers, some research explores recurrent neural networks (RNNs) and LSTMs, with mixed results. Recent findings highlight various causal sequence models and state space models also achieving ICL. However, MLPs’ potential for ICL remains underexplored despite their resurgence in complex tasks, prompted by the introduction of the MLP-Mixer model.
In this study researchers from Harvard demonstrate that multi-layer perceptrons (MLPs) can effectively learn in-context. MLPs and MLPMixer models perform competitively with Transformers on ICL tasks within the same compute budget. Particularly, MLPs outperform Transformers in relational reasoning ICL tasks, challenging the belief that ICL is unique to Transformers. This success suggests exploring beyond attention-based architectures and indicates that Transformers, constrained by self-attention and positional encodings, may be biased away from certain task structures compared to MLPs.
The study investigates MLPs’ behavior in ICL through two tasks: in-context regression and in-context classification. For ICL regression, the input is a sequence of linearly related value pairs (xi, yi), with varying weights β and added noise, plus a query xq. The model predicts the corresponding yq by inferring β from the context exemplars. For ICL classification, the input is a sequence of exemplars (xi, yi) followed by a query xq, sampled from a Gaussian mixture model. The model predicts the correct label for xq by referencing the context exemplars, considering data diversity and burstiness (Number of repeats per cluster in the context).
MLPs and Transformers were compared on in-context regression and classification tasks. Both architectures, including MLP-Mixers, achieved near-optimal mean squared error (MSE) with sufficient computing, although Transformers slightly outperformed MLPs for smaller computing budgets. For longer context lengths, vanilla MLPs performed worse, while MLP-Mixers maintained optimal MSE. As data diversity increased, all models transitioned from IWL to ICL, with Transformers making the transition more quickly. In in-context classification, MLPs performed comparably to Transformers, maintaining relatively flat loss across context lengths and transitioning from IWL to ICL with increased data diversity.
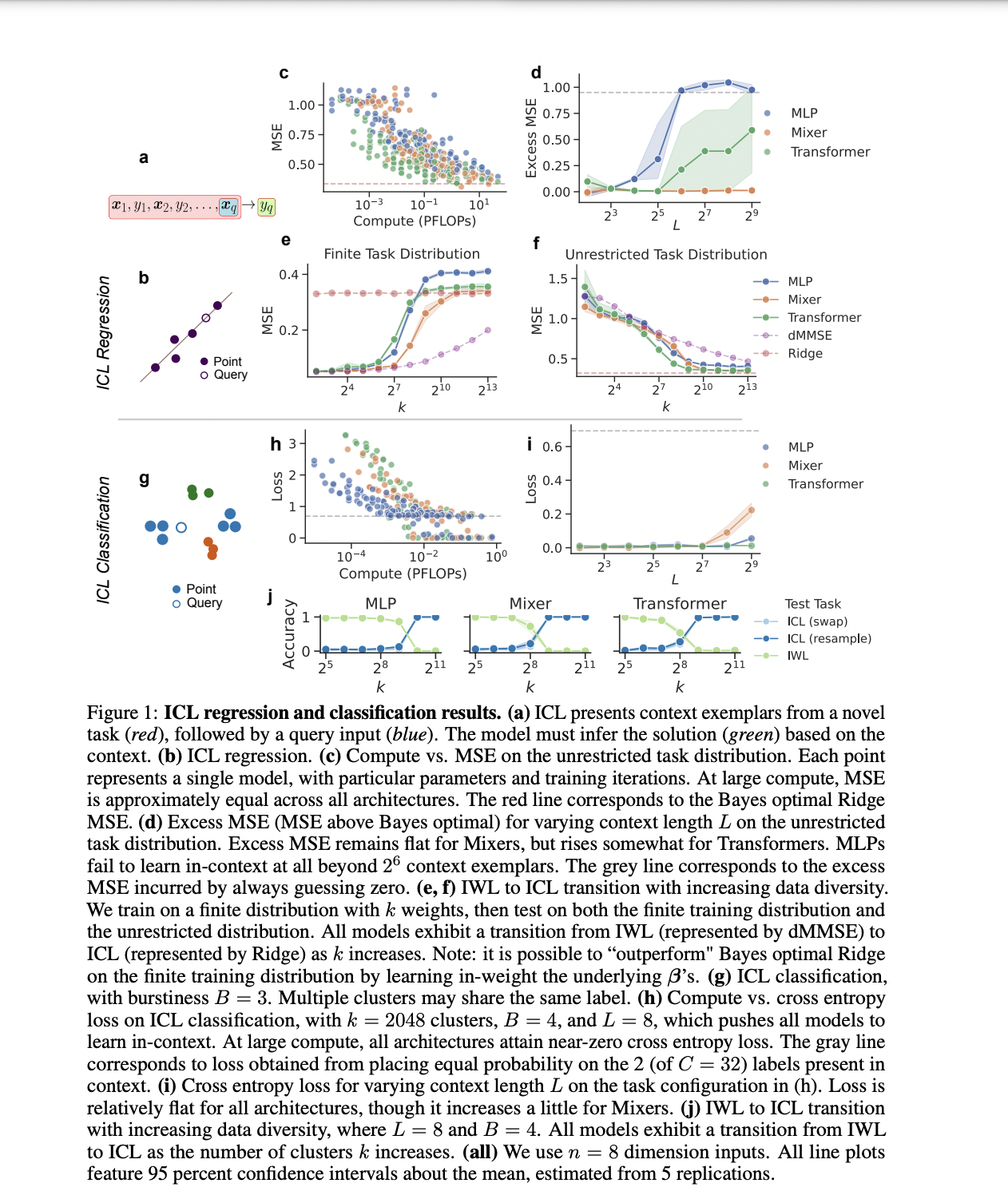
In this work, Harvard researchers compare MLPs and Transformers on in-context regression and classification tasks. All architectures, including MLP-Mixers, achieved near-optimal MSE with sufficient compute, although Transformers slightly outperformed MLPs with smaller compute budgets. Vanilla MLPs performed worse with longer context lengths, while MLP-Mixers maintained optimal MSE. As data diversity increased, all models transitioned from IWL to ICL, with Transformers making the transition more quickly. In in-context classification, MLPs performed comparably to Transformers, maintaining flat loss across context lengths and transitioning from IWL to ICL as data diversity increased.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 43k+ ML SubReddit | Also, check out our AI Events Platform
The post In-Context Learning Capabilities of Multi-Layer Perceptrons MLPs: A Comparative Study with Transformers appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]